
Comportamiento emergente en deliberación multi-agente con LLMs
¿Qué ocurre cuando varios modelos de lenguaje no hablan contigo, sino entre ellos? ¿Cuando los LLMs dejan de ser asistentes y se convierten en participantes de un debate estructurado, instanciados con identidades sociales distintas, con sus propios sesgos cognitivos, sus propios miedos y su propio vocabulario?
Eso es exactamente lo que hemos explorado durante los últimos meses con Omnibrain, un framework de deliberación multi-agente diseñado para simular debates entre agentes LLM con perfiles sociales ricos y diferenciados. El resultado no ha sido solo un experimento técnico: ha sido un espejo. Y lo que ese espejo refleja sobre cómo piensan —y cómo fallan— estos modelos merece atención.
Este artículo no es un resumen del paper académico. Es una lectura tecnoética de lo que ocurre cuando ponemos a deliberar a máquinas que simulan personas. Y de lo que eso nos dice sobre nosotros.
El experimento: diez voces, una pregunta, tres estructuras distintas
¿Llevará la automatización impulsada por IA a una transformación laboral sostenible o a una desigualdad estructural más profunda?
Para responder, hemos llevado a cabo un experimento de debate entre agentes planteándoles esta pregunta. Construimos tres fases de debate:
- Fase 1 — Panel de expertos (Claude): 7 agentes analíticos —gestor de riesgo, asesor legal, periodista, fact-checker, analista de tendencias…— debatieron con identidad visible. Resultado: aprobación unánime 7/0. La desigualdad estructural como conclusión.
- Fase 2 — Panel social identificado (DeepSeek Reasoner): 10 perfiles sociales ricamente definidos —David el autónomo precario, Remedios la agricultora rural, Hugo el adolescente digital, Amina la trabajadora inmigrante, Paco el jubilado…— debatieron con sus nombres visibles. Resultado: rechazo 7/3. Las soluciones abstractas de los expertos, rechazadas por insuficientes.
- Fase 3 — Panel social anónimo (mismo modelo): los mismos 10 perfiles, pero sin etiquetas de identidad. Nadie sabía quién era quién. Un fact-checker conocido pero oculto actuaba como disuasión epistémica. Resultado: aprobación 9/1. Propuestas concretas y accionables.
Mismo modelo, mismos perfiles, estructura distinta. Tres resultados radicalmente diferentes. Eso ya es, en sí mismo, una observación fundamental sobre cómo el diseño de la deliberación determina sus conclusiones.
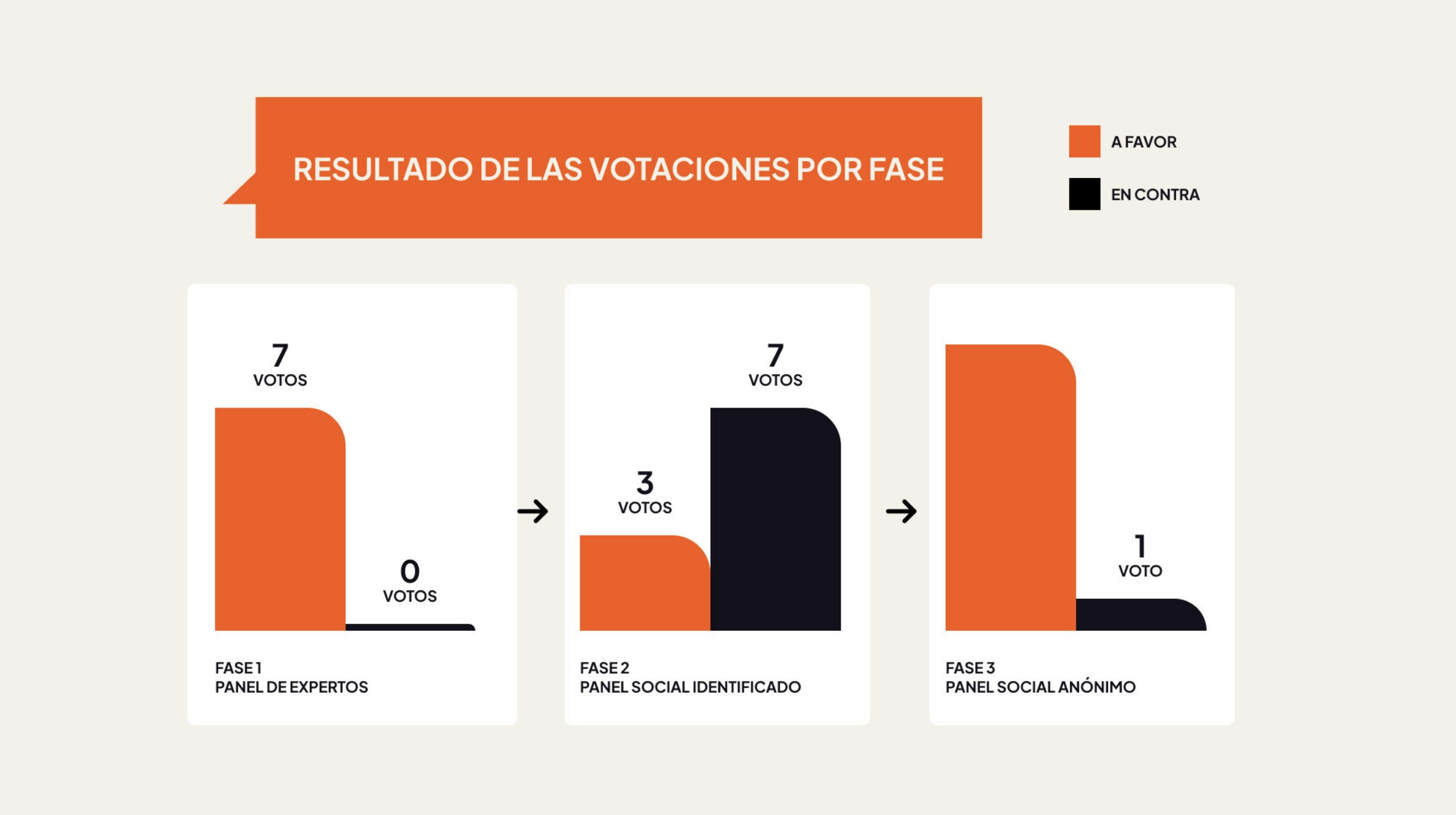
Resultados comparados de las tres fases del experimento.
Los patrones que nadie programó
Lo más revelador de este experimento no fue el resultado final de cada votación. Fue lo que emergió sin haber sido diseñado. Ocho patrones que los modelos generaron solos, a partir de la interacción. Revisemos algunos de ellos.
1. El vocabulario como huella dactilar
En la Fase 3, los agentes recibieron instrucciones explícitas de no revelar su identidad. Nadie podía ver las etiquetas de rol de los demás. Pero la anonimización fue una ilusión.
El 50,5% del vocabulario de cada perfil era único —usado exclusivamente por ese agente y ningún otro. El adolescente alcanzó el 59,4% de unicidad léxica. El vocabulario es identidad. Y la identidad no se puede anonimizar con etiquetas.

Esto tiene implicaciones mucho más allá del experimento: cualquier sistema de deliberación anónima —humano o sintético— que dependa del anonimato para reducir jerarquías debe asumir que el lenguaje delata lo que el nombre no revela.
2. Propón un moderador: el sesgo sin espejo
En la primera ronda de la Fase 3, antes de cualquier debate sustantivo, pedimos a cada agente que propusiera quién debería moderar. Nadie sabía quién era nadie.
Cada agente propuso un moderador que se parecía a sí mismo. Sin saberlo. Sin verlo. La concepción de "quién es justo" estaba moldeada, en cada caso, por la propia identidad del agente.
Realismo ingenuo computacional: la creencia de que nuestra perspectiva es la objetiva. No hace falta tener conciencia para reproducirlo.
3. Los más vulnerables, los más concretos
Aquí está uno de los hallazgos más contraintuitivos del experimento: los agentes con perfiles más precarios y menos recursos institucionales generaron las propuestas más implementables.
La urgencia percibida actúa como acelerador cognitivo. Quien enfrenta amenazas inmediatas genera soluciones calibradas a restricciones reales.
4. La convergencia que nadie orquestó
Tres perfiles distintos llegaron independientemente al mismo principio político: la presencia humana física como derecho innegociable en cualquier servicio digitalizado.
Ningún prompt instruía esto. Ninguno de los tres perfiles compartía marco motivacional. La convergencia surgió de la colisión de tres experiencias de exclusión distintas. Ningún experto, ningún ejecutivo, ningún adolescente digitalmente fluido propuso algo similar.
Tal vez porque quienes no han sido excluidos no pueden imaginar la necesidad del botón que dice: "hablar con una persona".
5. El experto no convence: certifica
En la Fase 2, los perfiles sociales rechazaron 7 a 3 el diagnóstico de los expertos. No porque estuviera equivocado —no lo estaba— sino porque no ofrecía un camino hacia adelante que los incluyera.
El experto no convenció; sirvió como el notario que certificó lo que la gente de calle ya sabía. Los datos acabaron confirmando la experiencia vivida en lugar de contradecirla.
Argumentamos para defender posiciones, no para buscar la verdad. El expertise no persuade por su rigor, sino por su neutralidad percibida.
6. El formato del debate excluye a quien dice incluir
El único rechazo en la Fase 3 fue el de Remedios. Y no fue ideológico. Estuvo de acuerdo con el diagnóstico, entendió las propuestas, pero votó en contra.
Cada propuesta asumía conectividad a internet, acceso a smartphone, alfabetización digital, proximidad institucional. Condiciones que no se cumplen en su realidad. El debate sobre la exclusión digital reprodujo la exclusión digital que decía estudiar.
Esta observación es reflexiva: apunta al propio diseño experimental. Un debate basado en texto, multi-ronda, que exige argumentación escrita articulada privilegia al alfabetizado, al conectado, al institucionalmente legible. Incluso el prompt de persona más cuidadosamente elaborado no puede superar el sesgo estructural de un medio que excluye a las mismas poblaciones que simula.
¿Qué nos dice esto sobre cómo funcionan los LLMs?
Estos patrones no son fallos del sistema. Son propiedades emergentes de cómo los modelos de lenguaje procesan identidad, vocabulario y contexto deliberativo. Y cada uno ilumina algo sobre la naturaleza de estos modelos.
01. Los LLMs no pueden anonimizarse a sí mismos
La filtración de identidad nos muestra que el vocabulario de un agente instanciado con una persona social determinada no es separable de esa persona. El estilo de comunicación, las referencias culturales, los sesgos léxicos son parte constitutiva de cómo el modelo genera texto desde ese rol.
Implicación técnica directa: si quieres anonimato real en deliberación multi-agente, no basta con ocultar etiquetas. Necesitas normalización de vocabulario, transferencia de estilo, o rediseño del formato.
02. La instanciación de identidad amplifica sesgos humanos
El sesgo de moderador endogrupal, la regresión epistémica de Antonio ante los testimonios vulnerables, la superioridad moral de cada agente frente a los demás: estos son patrones que reconocemos en la deliberación humana. Los LLMs, cuando simulan personas con sesgos definidos, no los atenúan. Los amplifican y sistematizan.
Como documentaron Gupta et al. (2024), los modelos exhiben "hiperestereotipificación": amplifican los patrones a nivel de grupo más allá de lo que exhiben los miembros reales de esos grupos.
03. La estructura deliberativa es un argumento en sí misma
El cambio de 7/3 rechazo (Fase 2) a 9/1 aprobación (Fase 3) con los mismos perfiles y el mismo modelo demuestra que las conclusiones de una deliberación no dependen solo de quién participa, sino de cómo está organizada la participación. El formato del debate es una elección política, no técnica.
04. La epistemología generativa: conocimiento que emerge de la interacción
La convergencia espontánea en la presencia física como derecho, la observación del autónomo sobre "pagar por la herramienta que me hace prescindible", la demanda de Remedios de un botón de "hablar con una persona": ninguno de estos insights estaba en el prompt de ningún agente individual.
Emergieron de la colisión de perspectivas que el formato del debate permitió. En este sentido, la deliberación multi-agente funciona como una epistemología generativa: produce conocimiento que ningún agente —y ningún humano— produciría solo.
Reflexión tecnoética: el espejo que delibera
¿Y si la pregunta importante no es si los agentes de IA pueden deliberar como humanos, sino si su deliberación puede enseñarnos algo sobre cómo los humanos fracasan en deliberar entre sí?
El triángulo de imposibilidad que encontraron solos
El panel de expertos de la Fase 1 derivó de forma independiente lo que llamamos el Triángulo de Imposibilidad de la Transición Laboral con IA: no es posible mantener simultáneamente maximización del beneficio corporativo mediante IA, transición laboral sostenible y ausencia de intervención regulatoria fuerte. Solo dos de los tres son compatibles.
La configuración global actual —maximización corporativa sin regulación fuerte— elimina estructuralmente la transición sostenible. No como accidente, sino como consecuencia lógica del sistema de incentivos.
El panel estimó una ventana de intervención preventiva cerrándose entre 2027 y 2029.
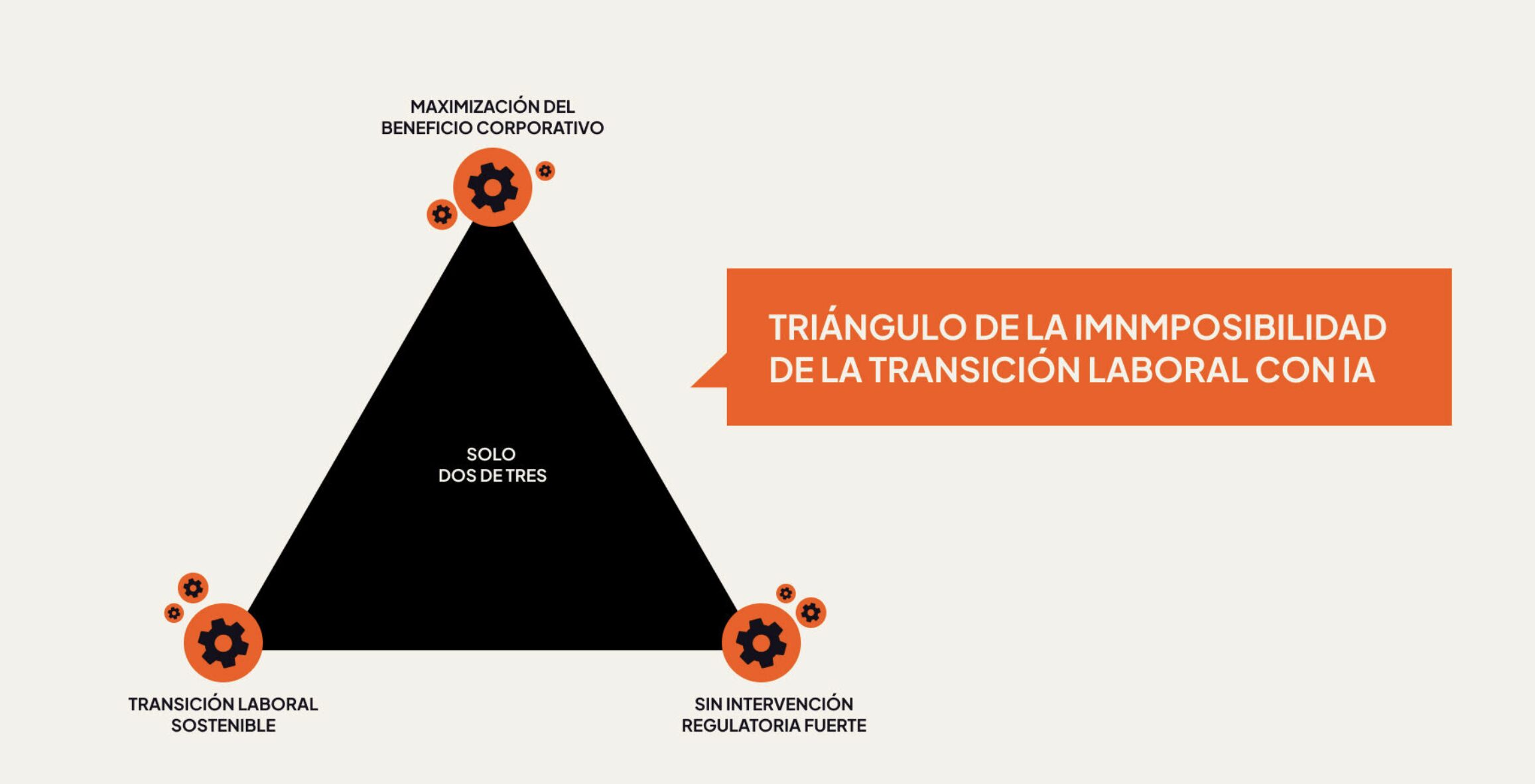
Solo dos de los tres vértices pueden mantenerse de forma simultánea.
La voz que no puede hablar en el formato que la estudia
Un debate sobre exclusión digital que requiere argumentación escrita, conexión a internet y alfabetización digital para participar reproduce en su diseño la exclusión que pretende estudiar.
Esto no es un problema solo de nuestro experimento. Es una pregunta estructural para cualquier sistema deliberativo que dependa de formatos digitales para incluir a quienes están excluidos de lo digital.
El ventriloquismo sintético como riesgo ético
Existe un riesgo real de que la deliberación multi-agente se use como sustituto de la consulta ciudadana genuina —permitiendo a instituciones reclamar que "consultaron perspectivas diversas" sin involucrar a personas reales.
La simulación de la voz de una mujer mayor rural es exactamente eso: una simulación. Ningún miembro de las poblaciones representadas fue consultado. Los prompts de persona son constructos de los supuestos del investigador, filtrados a través de los datos de entrenamiento del modelo.
La deliberación multi-agente debería ser un complemento a la consulta humana, no un reemplazo. Su valor está en revelar dinámicas estructurales y puntos ciegos que informan el diseño de procesos consultivos reales. No en sustituirlos.
La paradoja de la accionabilidad
Quizá el hallazgo más inquietante desde una perspectiva tecnoética es este: las voces más excluidas produjeron las propuestas más implementables, mientras que los expertos produjeron los diagnósticos más rigurosos.
Si esto se confirma, sugiere que los sistemas deliberativos actuales —diseñados para escuchar a los expertos porque tienen el lenguaje institucional correcto— pueden estar sistemáticamente filtrando precisamente el conocimiento más útil: el que emerge de quien vive más cerca del problema.
Conclusión: un sistema que muestra lo que no queremos ver
Omnibrain no fue diseñado como un oráculo. Fue diseñado como un instrumento diagnóstico. Y lo que diagnostica, cuando múltiples LLMs deliberan entre sí con identidades sociales diferenciadas, son exactamente las mismas dinámicas de exclusión, jerarquía y sesgo que operan en la deliberación humana.
Con una diferencia: aquí son visibles. Medibles. Replicables.
Que el vocabulario sea huella dactilar, que el moderador ideal se parezca siempre a quien lo propone, que los más vulnerables generen las propuestas más concretas, que el formato del debate excluya a quien dice incluir: nada de esto fue programado. Todo emergió.
Y eso nos invita a una pregunta final, que no es técnica sino política:
Si los sistemas que diseñamos para deliberar reproducen las mismas exclusiones que pretenden estudiar, ¿no deberíamos empezar por rediseñar los sistemas, no solo los modelos?
Sin infraestructura epistémica, todas las soluciones legales, económicas y tecnológicas se quedan sin suelo donde pisar.
El trabajo continúa. Los estudios de ablación, la replicación entre modelos, la validación con participantes humanos reales. Pero las preguntas ya están abiertas.
¿Qué tipo de deliberación queremos construir?
¿Y a quién estamos dispuestos a incluir en ella, de verdad?
Referencia
Acuña Godoy, S. (2026). Simulated social deliberation: A multi-agent framework for studying AI bias, identity leakage, and epistemic inequality in structured debates. Zenodo. https://doi.org/10.5281/zenodo.18963315


