
Por Daniel Contreras
¡Saludos, entusiasta de la tecnología! Si compartes la curiosidad por llevar la inteligencia artificial a tu propio equipo —sin depender de la nube, sin facturas de API y con tus datos bajo control—, esta serie es para ti. En esta primera entrega entenderás por qué ejecutar LLMs en local, qué modelos mirar en 2026, qué hardware necesitas y qué herramientas elegir.
En la Parte 2 montarás Ollama y lo conectarás a tu IDE; en la Parte 3, escalarás al equipo y decidirás cuándo compensa frente a la nube.
La ejecución de LLMs en local ha dejado de ser un experimento de entusiastas para convertirse en una opción seria y madura. En 2026, modelos como Llama 4, Qwen 3, DeepSeek R1 o Gemma 3 pueden ejecutarse en hardware de consumo con resultados que rivalizan con servicios en la nube.
Imagina la escena: son las diez de la noche, estás terminando un sprint y necesitas refactorizar un módulo
crítico que maneja datos de clientes. Abrir ChatGPT o Claude significaría pegar ese código en un servidor externo. Tu política de empresa lo prohíbe. Con un LLM local, en cambio, ese código nunca sale de tu portátil. El modelo procesa todo en tu máquina, te devuelve la sugerencia en segundos y tú sigues adelante sin comprometer la confidencialidad. Esta es la promesa —y la realidad— de la IA local en 2026.
Índice de esta entrega
- ¿Qué son los LLM y por qué ejecutarlos en local?
- El panorama actual en 2026: modelos, herramientas y tendencias
- Hardware: la realidad detrás de los requisitos
- Herramientas principales: Ollama, LM Studio, LocalAI y más
1. ¿Qué son los LLM y por qué ejecutarlos en local?
1.1. Los modelos de lenguaje grandes en pocas palabras
Los Large Language Models (LLM) son redes neuronales de aprendizaje profundo entrenadas con cantidades masivas de texto. Pueden comprender y generar lenguaje de forma muy natural: resumir documentos, traducir idiomas, responder preguntas, escribir código y mucho más. Piensa en GPT, Claude o Gemini: todos son LLM, pero ejecutados en servidores remotos.
Ejecutar un LLM en local significa tener ese «cerebro» corriendo en tu propio equipo (CPU o GPU) en lugar
de usar la nube. Es como tener un asistente superinteligente que vive en tu PC: te ayuda a codificar,
analizar datos o redactar documentos sin que ni un byte salga de tu máquina.
1.2. Las razones que impulsan la adopción local
Privacidad y control. Cada vez que pegas código propietario, credenciales o datos sensibles en ChatGPT o Claude, esa información viaja a servidores externos. En sectores regulados (sanidad, finanzas, defensa) o en empresas con políticas estrictas de confidencialidad, esto puede ser inaceptable. Con un LLM local, tus datos nunca abandonan tu equipo.
Coste. Las APIs de GPT-4o o Claude 3.5 Sonnet son potentes, pero la factura puede dispararse si haces
miles de llamadas al mes. Un modelo local elimina el coste por token: pagas la electricidad y el hardware, pero no hay factura de API.
Latencia. La pequeña pausa entre que preguntas y el texto empieza a fluir puede resultar molesta cuando
trabajas con autocompletado o refactorización en tiempo real. En local, con un modelo bien optimizado, la respuesta puede ser prácticamente instantánea.
Funcionamiento offline. ¿Programar en un avión, en el tren o en una zona con mala cobertura? Con un
LLM local, tu copiloto viaja contigo. No dependes de la conexión a internet. Esta ventaja es especialmente valiosa para equipos que trabajan en entornos con conectividad limitada o que viajan con frecuencia.
Personalización. Puedes ajustar parámetros, usar modelos especializados en código o en tu dominio, e incluso fine-tunear modelos para tareas concretas sin depender de lo que ofrezca un proveedor externo. Con Modelfiles en Ollama puedes definir system prompts por defecto, temperaturas y otros parámetros
para adaptar el modelo a tu estilo de trabajo.
Estudios recientes indican que los desarrolladores que usan herramientas de IA pueden aumentar su productividad entre un 40 % y un 55 %. La diferencia con un LLM local es que ese beneficio llega sin comprometer la privacidad ni el presupuesto.
1.3. Una anécdota que ilustra el valor
Un desarrollador backend en una fintech nos contó su experiencia: tenía que optimizar consultas SQL sobre tablas con datos reales de transacciones. Pegar esas queries en ChatGPT estaba prohibido por política de seguridad. Con Ollama y un modelo Qwen 2.5 Coder en su portátil, pudo iterar decenas de veces sobre las consultas sin que ningún dato saliera de su máquina. El resultado: redujo el tiempo de una query crítica de 8 segundos a menos de 1 segundo. Todo en local, sin una sola llamada a la nube.
2. El panorama actual en 2026: modelos, herramientas y tendencias
2.0. Breve contexto: de la nube al escritorio
Hace apenas tres o cuatro años, ejecutar un LLM en un ordenador personal era casi impensable. Los modelos requerían clusters de GPUs y millones de dólares en infraestructura. La democratización llegó por varios frentes: la liberación de pesos de modelos como LLaMA por Meta, las técnicas de cuantización que redujeron drásticamente los requisitos de memoria, y herramientas como Ollama o llama.cpp que empaquetaron todo en una experiencia usable. Hoy, un portátil de 1.500 euros puede ejecutar modelos que rivalizan con GPT-3.5 en muchas tareas. El salto cualitativo entre 2023 y 2026 ha sido enorme.
2.1. Modelos que dominan el ecosistema local
En 2026, el ecosistema de modelos open source ha madurado enormemente. Tres familias destacan por encima del resto:
DeepSeek R1 — El rey del razonamiento. Con 671B parámetros (37B activos gracias a Mixture-of-Experts), alcanza un 79,8 % en benchmarks de matemáticas AIME, superando ampliamente a GPT-4o. Su característica más llamativa son los «tokens de pensamiento» visibles: el modelo muestra su razonamiento paso a paso antes de dar la respuesta. Existen versiones destiladas (1,5B–32B) que corren en hardware de consumo con 24 GB de VRAM. Licencia MIT.
Llama 4 (Maverick y Scout) — Lo mejor en multimodalidad y eficiencia. Maverick: 400B parámetros (17B
activos), visión nativa y ventana de contexto de 1M tokens. Scout: 109B parámetros (17B activos) con una
ventana de contexto excepcional de 10M tokens. Alcanza un 88,2 % en MMLU. En cuantización 4-bit, Scout cabe en 24 GB de VRAM.
Qwen 3 — Referencia en código y entornos empresariales. Qwen 2.5 Coder 32B obtiene un 92 % en HumanEval. Qwen 3 72B es uno de los modelos densos más potentes, con excelente soporte multilingüe.
Licencia Apache 2.0, ideal para uso comercial.
Además, modelos como Mistral, Gemma (Google), Phi (Microsoft) y CodeLlama siguen siendo muy populares para tareas específicas. La tendencia es clara: modelos más pequeños pero mejor cuantizados y optimizados permiten resultados sorprendentes en hardware modesto.
Modelos recomendados por caso de uso (2026):

2.2. Tendencias técnicas que marcan 2026
Cuantización 4-bit (Q4_K_M): Reduce el uso de VRAM en torno a un 72 % con una pérdida de calidad de solo un 3–5 % respecto a FP16. Se ha convertido en el estándar de facto para ejecución local. En la práctica, esto significa que un modelo de 70B que en FP16 requeriría más de 140 GB de VRAM puede ejecutarse en unos 42 GB con cuantización Q4, haciéndolo viable en GPUs de gama alta de consumo.
Mixture-of-Experts (MoE): Modelos como DeepSeek R1 o Llama 4 activan solo una fracción de sus parámetros por inferencia, lo que permite escalar la capacidad sin multiplicar el coste computacional. En DeepSeek R1, de 671B parámetros totales solo se activan unos 37B por token generado; el
resultado es un modelo que razona como uno enorme pero con requisitos de hardware manejables.
Ventanas de contexto largas: Scout con 10M tokens o Maverick con 1M abren la puerta a analizar documentos enormes sin dividirlos en fragmentos. Antes, un informe de 100 páginas había que trocearlo y perder coherencia; ahora el modelo puede procesarlo de una vez.
Multimodalidad nativa: Visión + texto ya no es exclusivo de la nube. Modelos como Qwen3 VL 32B
ofrecen capacidades multimodales ejecutables en local: puedes enviar una captura de pantalla y pedir que describa el UI, o un diagrama y que extraiga la estructura.
Licencias y uso comercial: La mayoría de modelos open source (Llama, Qwen, Mistral, Gemma) permiten uso comercial bajo condiciones que varían por modelo. DeepSeek R1 usa MIT; Qwen suele usar Apache 2.0; Llama tiene una licencia de uso que permite comercialización con restricciones de volumen. Revisa siempre la licencia del modelo concreto que elijas si vas a usarlo en productos comerciales.
2.3. Benchmarks y comparativas reales
En pruebas realizadas con hardware típico (MacBook Pro M3 16 GB, RTX 4070 12 GB), estos son resultados orientativos de tokens por segundo en modo chat:
Llama 3.1 8B: 35–45 tok/s (Mac M3), 50–60 tok/s (RTX 4070)
Qwen 2.5 Coder 7B: 40–50 tok/s (Mac M3), 55–65 tok/s (RTX 4070)
DeepSeek R1 32B (distil): 8–12 tok/s (Mac M3 16 GB con swap), 18–22 tok/s (RTX 4070)
Llama 4 Scout 17B activos: 12–18 tok/s en 24 GB VRAM
La calidad percibida en tareas de código suele estar a la par de GPT-3.5 para modelos 7B–8B bien afinados, y se acerca a GPT-4 en tareas de razonamiento cuando se usan modelos de 32B o superiores. Para refactorización, documentación y generación de boilerplate, la diferencia con la nube es mínima en la práctica.
3. Hardware: la realidad detrás de los requisitos
3.1. VRAM: el cuello de botella que marca la diferencia
Olvídate por un momento de la velocidad del procesador. En el mundo de los LLM locales, la VRAM
(memoria de vídeo) o la RAM unificada (en Mac) determina qué modelos puedes ejecutar y con qué
fluidez.
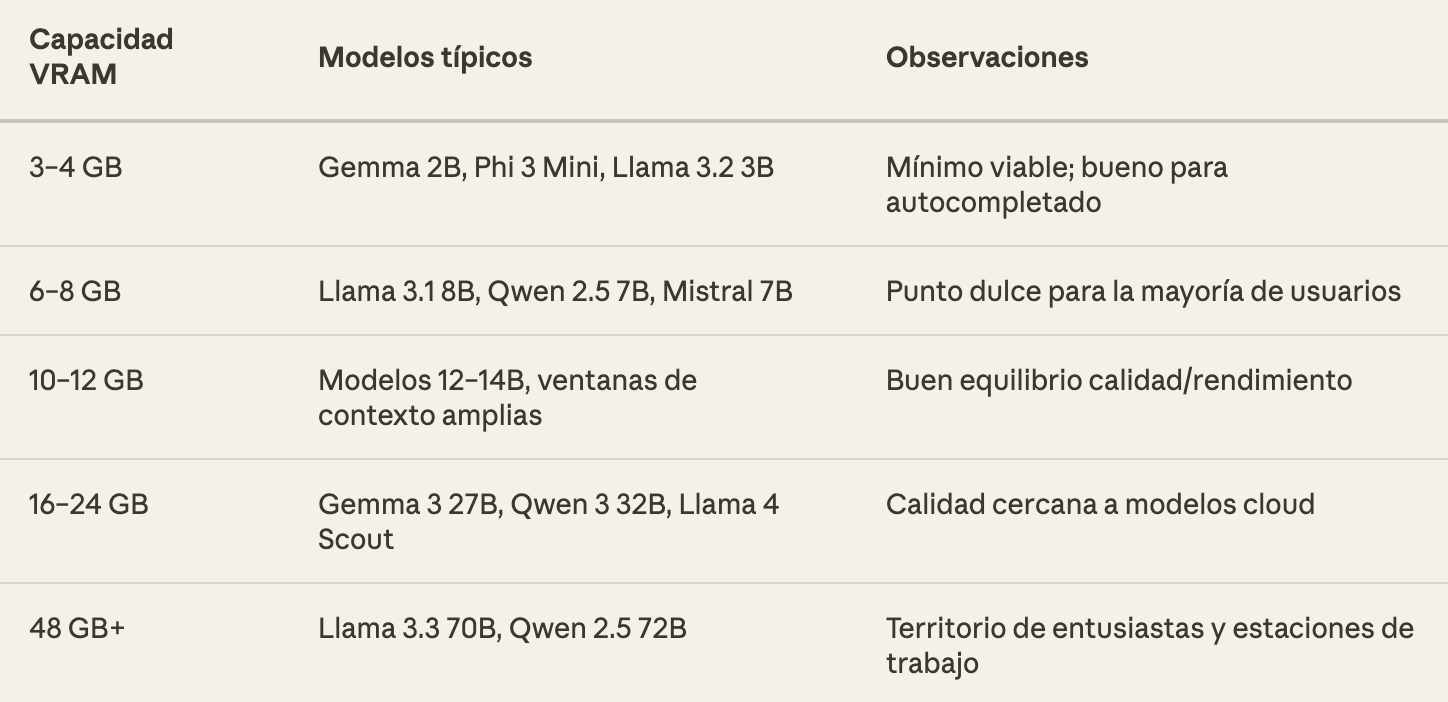
Referencia rápida por cuantización Q4_K_M: Un modelo 7B requiere ~5 GB, 8B ~6 GB, 14B ~10 GB, 32B ~20 GB y 70B ~42 GB. Además, la KV cache (caché de atención) crece con la longitud del contexto: un modelo 8B con contexto de 32K tokens puede necesitar ~4,5 GB solo para la caché.
3.2. Apple Silicon: la ventaja de la memoria unificada
Los Mac con chip M (M1, M2, M3, M4) tienen una ventaja estructural: la CPU y la GPU comparten la misma
memoria. Un Mac con 48 GB de RAM unificada puede ejecutar modelos de 32B que en un PC requerirían
una tarjeta gráfica de varios cientos de euros.
Rendimiento por configuración (datos orientativos 2026):
M4 Base (16–32 GB): Modelos 7B–14B; 7B a 25–45 tokens/segundo.
M4 Pro (24–64 GB): Modelos 14B–32B; 7B–14B a 25–40 tok/s.
M4 Max (128 GB): Modelos 70B a ~22 tok/s.
Importante: El ancho de banda de memoria importa más que la generación del chip. Un M3 Max (400 GB/s) puede generar tokens más rápido que un M4 Pro (273 GB/s). El M4 Max lidera con 546 GB/s.
En pruebas reales con un MacBook Pro M3 y 16 GB de RAM, modelos de 7B como DeepSeek Coder o Llama 3 funcionan con fluidez para desarrollo. Para modelos más grandes, 24 GB o más son recomendables.
3.3. GPU vs CPU
En Windows o Linux con GPU NVIDIA, Ollama y otras herramientas usan CUDA para acelerar la inferencia.
Sin GPU, la inferencia en CPU puede ser hasta 10–20 veces más lenta: el texto puede salir a 1–2 palabras
por segundo.
En Mac, la GPU integrada se aprovecha automáticamente gracias a Metal. No necesitas configuración adicional.
3.4. Espacio en disco y otros requisitos
Disco: Un modelo 7B ocupa ~4 GB; uno de 70B puede superar los 40 GB. Tener 50–100 GB libres es razonable si quieres varios modelos. Los modelos se almacenan en ~/.ollama (Linux/Mac) o C:\Users\<usuario>\.ollama (Windows). Si tienes un SSD pequeño, considera tener solo uno o dos modelos a la vez y eliminar los que no uses con ollama rm.
3.5. Escenarios reales por tipo de equipo
Portátil de empresa (8–16 GB RAM, sin GPU dedicada): Modelos 3B–7B. Gemma 2B, Phi-4 Mini, Llama 3.2 3B o Starcoder2 3B para autocompletado. Evita modelos de 14B o más; la experiencia será lenta o el sistema se quedará sin memoria.
MacBook Pro M3/M4 (16–36 GB RAM unificada): El punto dulce. Modelos 7B–14B van fluidos. Con 36 GB puedes probar 32B en cuantización Q4. La memoria unificada es una ventaja enorme frente a PCs con RAM y VRAM separadas.
PC con RTX 3060/4060 (8–12 GB VRAM): Modelos 7B–14B. Excelente rendimiento. Con 12 GB puedes
probar 14B o versiones cuantizadas de 32B si el contexto no es muy largo.
PC con RTX 3090/4090 (24 GB VRAM): Territorio premium. Modelos 32B–70B en cuantización.
DeepSeek R1 32B, Llama 4 Scout, Qwen 3 32B. La experiencia se acerca mucho a la de servicios en la
nube.
Servidor sin GPU (solo CPU): Viable para modelos 3B–7B si tienes paciencia. La inferencia puede ser de 2–5 tokens por segundo. Útil para tareas batch o de bajo volumen, no para interacción en tiempo real.
- CPU: Para modelos 7B–14B, un CPU de 6–16 núcleos (Intel i5–i7, AMD Ryzen 5–7) es suficiente para
tokenización y preparación de datos. - Python 3.8+ y Git son útiles para scripts y herramientas complementarias.
Nota sobre equipos antiguos: Si tu portátil tiene menos de 8 GB de RAM libre, la experiencia con modelos locales puede ser frustrante. En ese caso, considera usar un servidor Ollama compartido en la red local (un compañero con un equipo más potente o un servidor de desarrollo) y conectarte desde tu IDE a esa instancia. La configuración es la misma: solo cambia localhost por la IP del servidor.
4. Herramientas principales: Ollama, LM Studio, LocalAI y más
4.1. Ollama: el estándar de facto
Ollama es la herramienta más popular para ejecutar LLMs localmente. Pensada para desarrolladores, ofrece una CLI sencilla y una API REST compatible con OpenAI. Está construida sobre llama.cpp y soporta NVIDIA, AMD y Apple Silicon. Su filosofía es similar a la de Docker: empaqueta la complejidad (descarga de modelos, gestión de dependencias, optimizaciones de inferencia) en una experiencia de un solo comando. Por eso se ha convertido en el estándar de facto para quien quiere empezar rápido sin perder flexibilidad.
Ventajas: Estable, open source, API compatible con OpenAI, excelente rendimiento en tokens por segundo, soporte multiplataforma.
Limitaciones: No incluye interfaz de chat integrada; para eso se usa Open WebUI u otras alternativas.
Ideal para: Desarrolladores, integración con IDEs, uso por API, entornos de producción controlados.
4.2. LM Studio: la opción visual
LM Studio ofrece una interfaz gráfica pulida: descubrimiento de modelos, descarga integrada y chat
incorporado. Es muy amigable para quienes prefieren no tocar la terminal.
Ventajas: Interfaz intuitiva, chat integrado, buena para prototipado rápido, funciona bien en máquinas
modestas.
Limitaciones: Problemas de estabilidad documentados (fugas de memoria, cierres inesperados con modelos 70B+), sin soporte Docker, uso principalmente en escritorio.
Ideal para: Principiantes, experimentación rápida, máquinas con especificaciones bajas.
4.3. LocalAI: flexibilidad y multimodalidad
LocalAI destaca por su flexibilidad: soporta múltiples formatos (GGUF, PyTorch, GPTQ, AWQ, Safetensors) y ofrece una interfaz web incluida. Tiene soporte maduro para tool-calling y aplicaciones multimodales.
Ventajas: Multimodal, múltiples formatos de modelo, API estable, interfaz web integrada.
Ideal para: Proyectos que requieren visión + texto, formatos de modelo no estándar, aplicaciones con tool- calling.
4.4. Otras opciones según el caso de uso
- vLLM: Pensado para producción y alto rendimiento. Excelente para servir muchos usuarios o batches
grandes. Menos adecuado para uso personal en un solo equipo. - Jan: Enfocado en privacidad y control total. Interfaz tipo ChatGPT, todo local.
- Open WebUI: Frontend web para Ollama. Convierte tu instancia local en una interfaz tipo ChatGPT
con gestión de conversaciones, modelos y plugins.
4.5. Resumen comparativo

4.6. Cuándo pasar de Ollama a otras herramientas
Ollama cubre el 90 % de los casos de uso para desarrolladores.
Considera alternativas cuando:
- Necesitas throughput muy alto (muchas peticiones por segundo): vLLM está optimizado para esto.
- Necesitas formatos de modelo que Ollama no soporta (por ejemplo, modelos en formato Safetensors sin conversión a GGUF): LocalAI es más flexible.
- Quieres una interfaz tipo ChatGPT sin configurar nada: Jan o Open WebUI sobre Ollama.
- Tu equipo no es técnico y necesita algo «que funcione»: LM Studio con su interfaz gráfica puede
ser más accesible.
4.7. ¿Cuál elegir según tu situación?
- Soy desarrollador y quiero integrar con mi IDE: Ollama. Sin duda.
- No me gusta la terminal y quiero probar rápido: LM Studio.
- Necesito visión + texto o formatos de modelo raros: LocalAI.
- Tengo un servidor potente y quiero servir a muchos usuarios: vLLM.
- Quiero una interfaz tipo ChatGPT sin configurar nada: Jan o Open WebUI sobre Ollama.
4.8. Open WebUI: el frontend que convierte Ollama en ChatGPT
Si quieres una interfaz web tipo ChatGPT para tu Ollama local, Open WebUI es la opción más popular. Se
instala como contenedor Docker y se conecta a tu instancia de Ollama:

Abre http://localhost:3000 en tu navegador y tendrás una interfaz con chat, historial de conversaciones, selección de modelos y plugins. Todo el procesamiento sigue ocurriendo en tu Ollama local; Open WebUI es solo el frontend. Es especialmente útil si quieres que personas no técnicas (product managers, analistas) puedan probar el modelo sin tocar la terminal ni configurar un IDE.
Siguiente paso: monta tu copiloto
Ya sabes por qué tiene sentido local, qué modelos mirar en 2026 y si tu equipo aguanta un 7B o un 32B. También conoces el mapa de herramientas —con Ollama como estándar para desarrolladores.
Continúa en la Parte 2: Monta tu copiloto local — Ollama, tu IDE y casos de uso reales, donde instalarás Ollama, conectarás VS Code, Continue, Cline o Cursor y tendrás un flujo de trabajo en 15 minutos.
Despedida
Esperamos que esta primera entrega te haya dado una base sólida para entender el panorama local de los LLM y elegir con criterio tu punto de partida. En la siguiente parte lo llevamos a la práctica completa con instalación, IDE y flujos de trabajo reales.


