
A lo largo de la historia las formas de interacción entre los ordenadores y las personas han ido evolucionando. Desde los primeros medios utilizados con el uso de tarjetas perforadas, hasta la evolución al uso de teclados y ratones, junto con la aparición más recientemente de pantallas táctiles.
El presente y futuro de la interacción humano-máquina está marcado por el uso del lenguaje humano. El reconocimiento automático del habla (o ASR por sus siglas en inglés) existe desde hace décadas, pero sólo recientemente ha empezado a ser más sofisticado, y se ha convertido en un medio de interacción cada vez más usado y sobre el cual se asientan un número en aumento de tecnologías. Esta técnica permite a los humanos utilizar su voz, expresándose de una forma natural, para comunicarse con una interfaz informática.
Para obtener una interpretación aceptable del habla, hay que combinar un conjunto de información procedente de distintas fuentes de conocimiento, como son la acústica, fonética, léxico, sintaxis, semántica… Un sistema ASR tendrá que ser capaz de hacer frente a la unión de estas fuentes en las que además, habrá presentes ambigüedades, incertidumbres y errores inevitables.
Un Sistema ASR se compone principalmente de las siguientes partes:
-
Modelos Acústicos: Buscan modelar la conversión de una secuencia de ondas sonoras en una secuencia de letras.
-
Modelos del Lenguaje: Aporta conocimiento sobre el lenguaje a la formación de las palabras y frases a partir de lo dado por el modelo acústico.
El audio será primeramente modelado por un modelo acústico, que buscará transformar las ondas sonoras, que conforman el habla en la secuencia de letras que componen el discurso. Lo que obtendremos a la salida de un modelo acústico será la distribución de probabilidad que el modelo da a cada una de las letras en para cada instante. Esto formará un espacio de búsqueda en el que, con el uso de un modelo de lenguaje determinaremos la letra más probable utilizando el conocimiento en base a la sintaxis, la semántica y el léxico del lenguaje, que este modelo de lenguaje nos aporta.
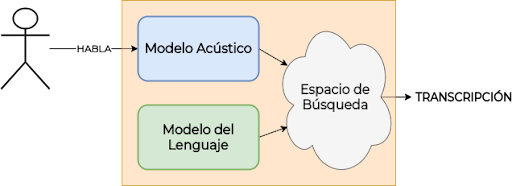
Funcionamiento de sistema ASR.
Dentro de todo esto, las arquitecturas basadas en redes neuronales están cambiando las reglas del juego. Los avances están permitiendo transformar las distintas disciplinas de la Inteligencia Artificial, como pueden ser el Procesamiento del Lenguaje Natural (NLP), la Visión por Computador (CV) o el Reconocimiento Automático del Habla (ASR). La aparición de modelos basados en arquitecturas complejas de Deep Learning, como los Transformers, están permitiendo obtener resultados nunca antes vistos, y a su vez obtenemos modelos muy fácilmente reusables en diferentes tareas o campos.
En cuanto a la evolución de los modelos acústicos, estos también se han visto muy beneficiados por la aparición de estas complejas arquitecturas de redes neuronales, pasando por el uso de modelos de Machine Learning más tradicionales como pueden ser los Modelos de Mixturas Gausianas (GMM,) o los Modelos Hidden Markov (HMM), hacia modelos basados en redes neuronales como las recurrentes (RNNs), las convolucionales (CNNs) o los Transformers.
Los modelos que hoy establecen el estado del arte, y que están siendo más ampliamente desarrollados y utilizados, son los que hacen uso en conjunto de estos dos últimos tipos de arquitecturas de redes neuronales, las CNNs junto con Transformers.
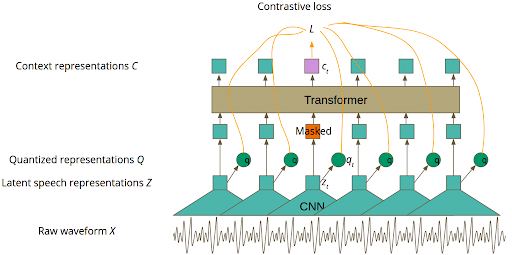
Arquitectura del modelo Wav2Vec 2.0.
La combinación de ambos tipos de arquitecturas dentro de un mismo modelo permite beneficiarse de cada una de las características que aporta cada una de ellas.
Por un lado, las CNNs permiten representar en un espacio dimensional reducido a las características encontradas en ventanas temporales del audio de entrada al modelo. Esto lo consiguen gracias a una operación matemática llamada convolución. Esta se encarga de transformar los datos de entrada, de tal manera que ciertas características y patrones se vuelven más dominantes en la salida al tener un valor numérico más alto asignado.
Por otro lado, los Transformers consisten en un Encoder-Decoder (Seq2Seq) con un mecanismo de Auto-Atención. El Encoder recibe una secuencia de entrada (en este caso la representación vectorial lograda por CNN) que transformará en una representación interna posteriormente usada por el Decoder para transformarla en el tipo de secuencia buscada. En el caso de los modelos acústicos corresponde con la transcripción a las letras del abecedario. A lo largo de toda la arquitectura intervendrá un mecanismo de Auto-Atención. Este se encargará de decidir qué partes de la secuencia son más relevantes con respecto a otras, para así lograr una representación contextualizada de la secuencia de entrada.
Algunos de los modelos acústicos que establecen el Estado del Arte serían los siguientes: Wav2Vec 2.0, XLSR-53, HuBERT o UniSpeech-SAT. Todos ellos se basan en la arquitectura que hemos comentado previamente, con ligeras variaciones o mejoras introducidas, principalmente en cómo se entrenan estos modelos. Cabe destacar entre todos ellos XLSR-53, cuyo objetivo es hacer una representación multilenguaje del habla, de forma que, pueda ser fácilmente adaptable a tareas con distintos lenguajes.
Aparte de los excelentes resultados dados en multitud de tareas por este tipo de modelos, una de sus características más destacables es la facilidad con la que se pueden adaptar a diversas de tareas, haciendo uso de una cantidad de datos etiquetados mucho menor que la que previamente se requería para otros tipos de modelos.
Con el objetivo de ilustrar la facilidad de uso de este tipo de modelos que constituyen el estado del arte, en los siguientes apartados se irá detallando cómo utilizar alguno de estos modelos en Python. Más concretamente se utilizará un sistema ASR para la transcripción del habla en español. Para ello, se hará uso de la librería Transformers desarrollada por Huggingface, la cual nos permitirá disponer de una API en Python, que nos permite descargar, usar y/o entrenar modelos contenidos en su propio repositorio público.
En primer lugar habrá que encontrar el modelo que mejor se adapte a nuestros requisitos, tanto en el idioma, la tarea a realizar, el backend utilizado por el modelo (TensorFlow, JAX o Pytorch), la licencia… Para ello accederemos al repositorio de modelos, e iremos filtrándolos según nuestros requisitos. Para el caso previamente descrito estos serían los resultados:
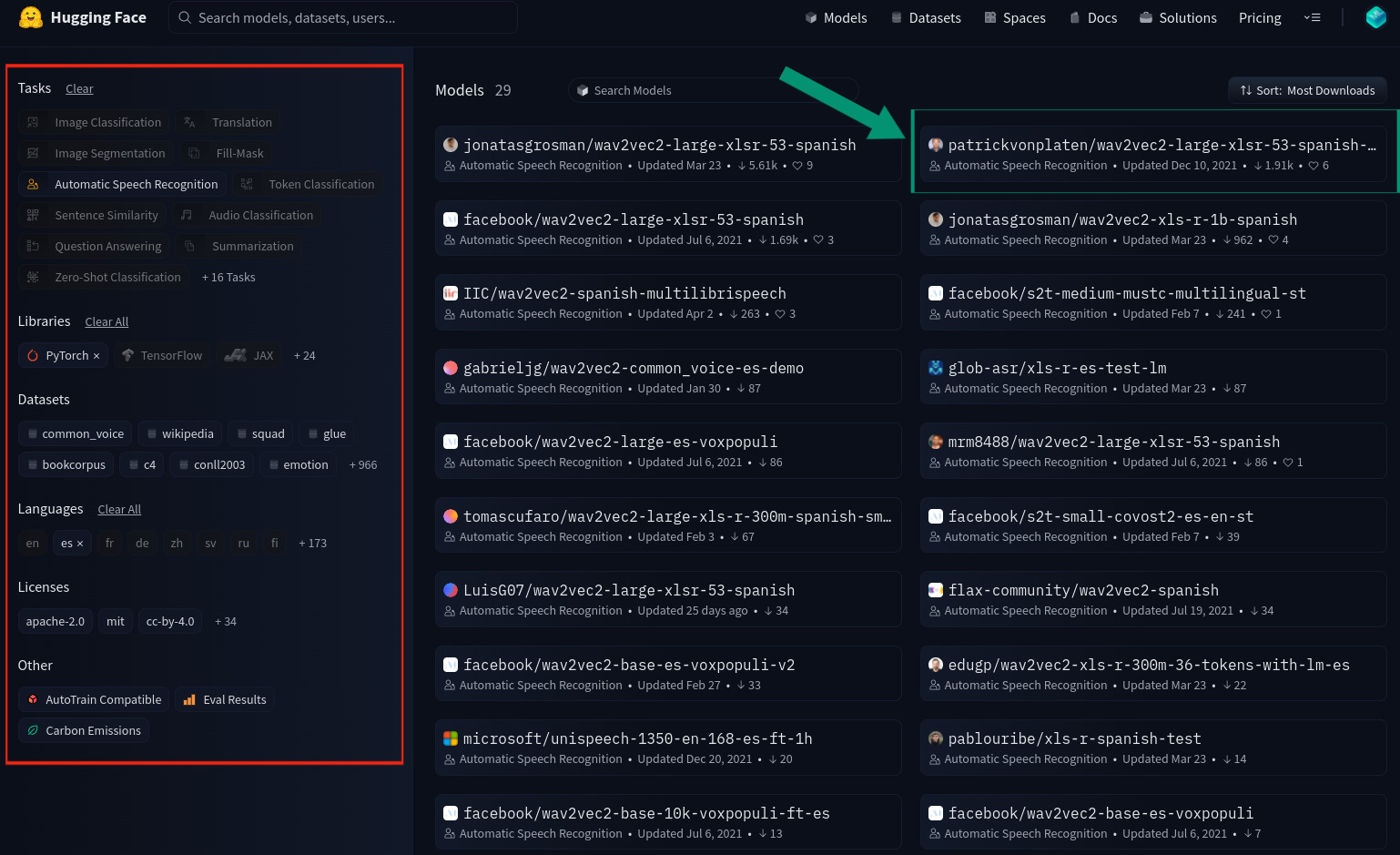
A la hora de elegir el modelo tenemos dos opciones: por un lado, tenemos sistemas ASR compuestos tanto por el modelo acústico como por el modelo del lenguaje como se detalló anteriormente. Por otro lado, tenemos tan solo modelos acústicos, que no hacen uso de ningún modelo de lenguaje para ayudarse de su conocimiento del lenguaje en la transcripción. Generalmente, los primeros obtendrán resultados notablemente superiores a los segundos por lo que en esta ocasión optamos por un sistema ASR completo con modelo del lenguaje. Este es el motivo por el que se ha elegido el modelo señalado con la flecha verde:
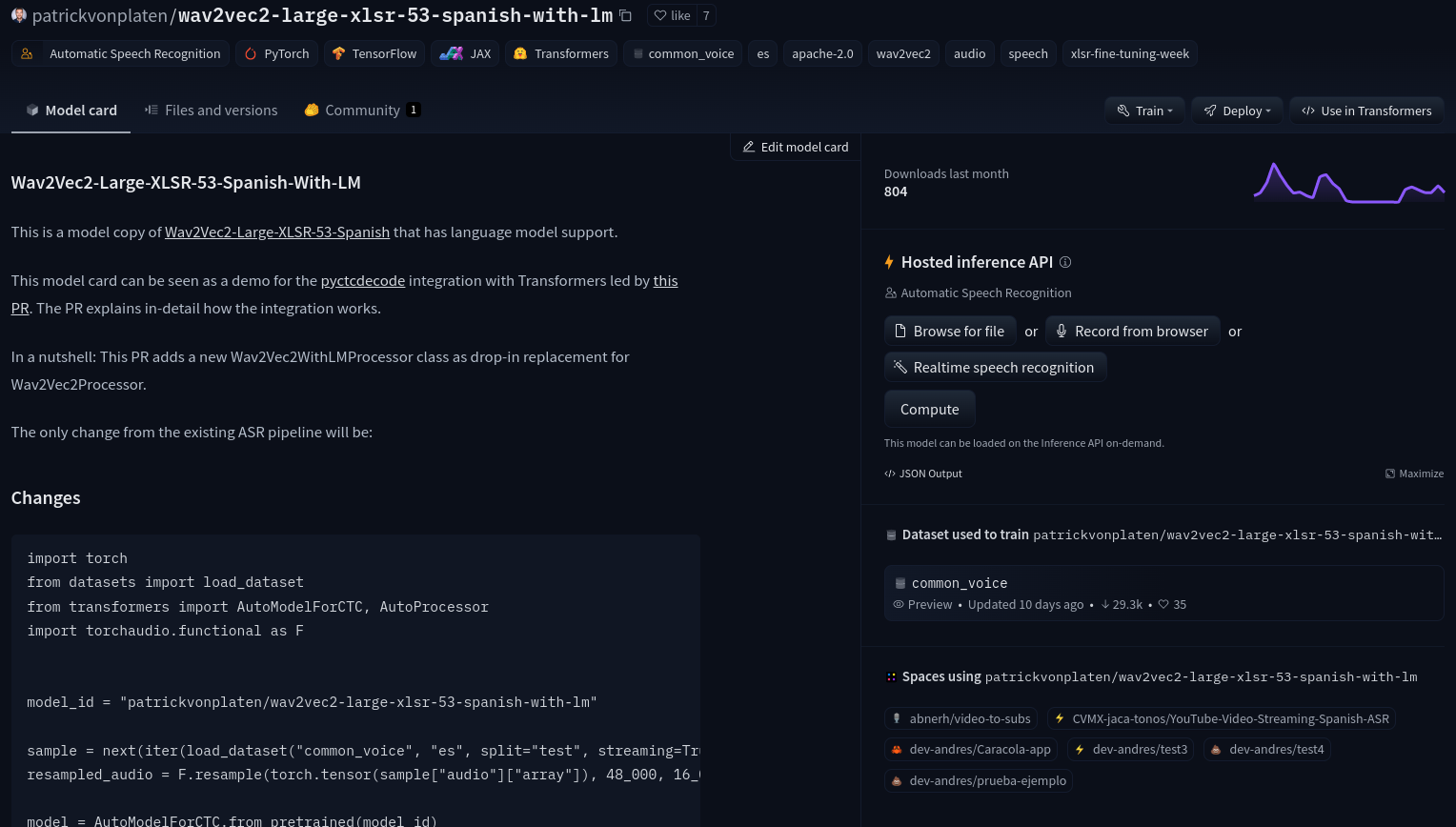 Dentro del repositorio de este modelo, el usuario que lo disponibilizó puede detallar todo tipo de información relativa a este, desde información general, datasets usados o estadísticas de descarga, hasta una API para probar el modelo al momento.
Dentro del repositorio de este modelo, el usuario que lo disponibilizó puede detallar todo tipo de información relativa a este, desde información general, datasets usados o estadísticas de descarga, hasta una API para probar el modelo al momento.
Una vez seleccionado este modelo, pasemos a Python para ilustrar cómo implementar un sistema ASR haciendo uso de nuestra elección.

Con tan solo tres líneas de código hemos sido capaces de implementar un sistema ASR, que hace uso del Estado del Arte en el modelo acústico que lo compone. Para ello, hemos hecho uso de las pipelines de Transformers, que nos permiten abstraer todo el procesado necesario para convertir el path de un audio en la transcripción de este. Con este fin, la pipeline toma como argumentos de entrada tanto el nombre del modelo que queremos utilizar, que fue el anteriormente seleccionado en el repositorio web, como la tarea para la que está pensada este modelo y la cual queremos realizar, que en nuestro caso fue el Reconocimiento Automático del Habla. Una vez creada la pipeline, podremos hacer uso de ella tan solo pasándole la ruta del audio que queremos transcribir, devolviéndonos de esta forma, el resultado de este procesado como una transcripción de este audio.
Esta sencilla librería nos permitirá hacer uso de los modelos más potentes y avanzados de la actualidad. Estos modelos han sido utilizados desde Kairós DS como parte de sistemas de IA en proyectos como Verbalizapp para la ayuda de pacientes con afasia.

