
Los datos son el nuevo petróleo de las empresas. Y, como tal, es necesario gestionar la logística para llevar esos datos a una refinería donde se procesen y, posteriormente, servir a todos los clientes con los derivados de dicho petróleo. En nuestro caso transformaremos y cruzaremos datos para conseguir, por ejemplo, generar KPIs de valor o niveles de calidad de datos para que posteriormente se exploten.
Para entender la complejidad que puede haber en un proceso de este tipo, debemos entender primero el concepto de flujo o pipeline de datos. El flujo de datos es el conjunto de acciones que se realizan sobre un dato para moverlo, limpiarlo y procesarlo, hasta el punto en el que pueda ser consumido. En ocasiones hablamos de las ETL de datos, donde movemos y procesamos datos de un lugar a otro para ser almacenados y tratados, los pipelines de datos incluyen procesos de ETL y, además, están orientados, no solo a la transferencia del dato, sino a aportar al final del pipeline un valor a negocio.
Dentro de las empresas se pueden manejar multitud de flujos de datos, desde aquellos que pueden generar sistemas de reporting, cuadros de mando o generar datos para actualización de modelos de ML, pero también flujos sencillos de captación y representación de datos para una aplicación. En cualquier caso, en muchas de estas ocasiones esos flujos de datos (que pueden ser más o menos complejos) tienen tal periodicidad, criticidad y dependencias que, ante un fallo, restaurar el flujo puede ser un verdadero dolor de cabeza.
Por ejemplo, imaginemos que diariamente se reciben por FTP unos ficheros CSV con la actualización de los últimos datos de canal digital de una empresa. Si estos datos no se procesan, puede ser que al día siguiente se sobrescriban y perdamos la información, o en caso de no perderla, ¿cómo podemos reprocesar parte de nuestros KPIs que agregan información cuando nos hemos saltado un día? Tareas como esta no resultan nada sencillas.
Para poder orquestar, gestionar, controlar y monitorizar esos flujos de datos existen herramientas en mercado como, por ejemplo, NIFI que está muy orientada streams, o Oziee cuando trabajamos con plataformas de Big Data Hadoop.
Sin embargo, hoy queremos hablarte de Airflow, y de cómo lo utilizamos en Kairós DS a la hora de realizar proyectos donde se requiera una orquestación de flujos de datos.
Airflow es una plataforma Open Source para la gestión de flujos de trabajo que utiliza Python como lenguaje de programación. Fue creada por Airbnb en 2014 y está disponible como proyecto Apache desde 2019.
Airflow te permite trabajar en modalidad standalone o sobre un cluster de kubernetes si necesitas escalar horizontalmente. También provee de una interfaz gráfica para ver el estado y gestión de los flujos, así como la monitorización y ejecución de los mismos.
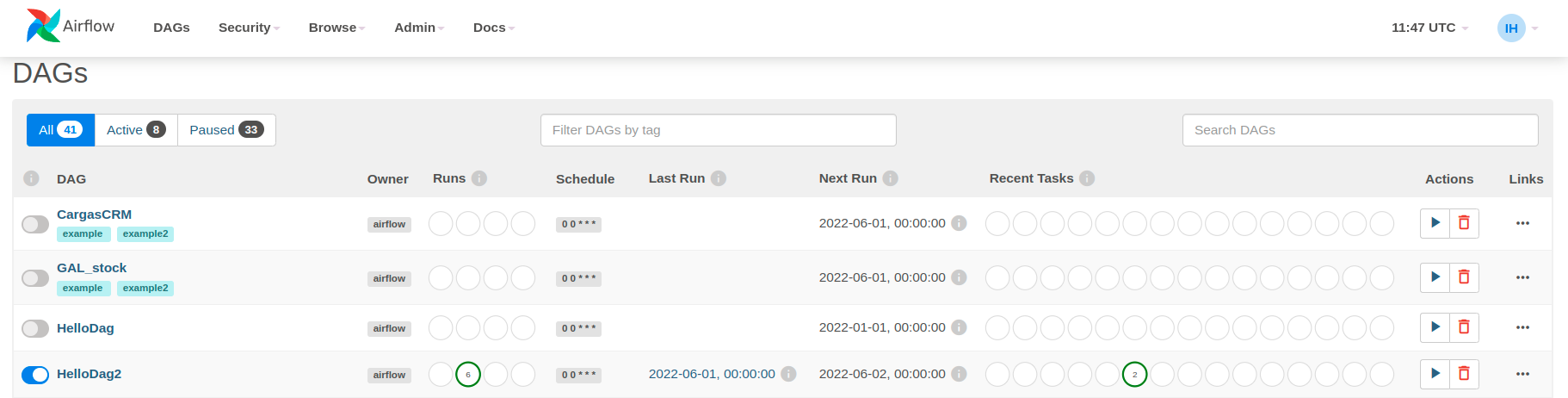
Cómo lo usamos en clientes en Kairós DS
Conceptos básicos: DAG, Task, Operator y XCOMs
Lo primero que debemos saber es que dentro de Airflow cualquier flujo de datos se modela como un DAG, un grafo dirigido acíclico, donde los nodos son tareas/task y las aristas dirigidas indican relación y orden entre tareas. Además, se trata de grafos acíclicos, es decir, que no contienen bucles en su interior.
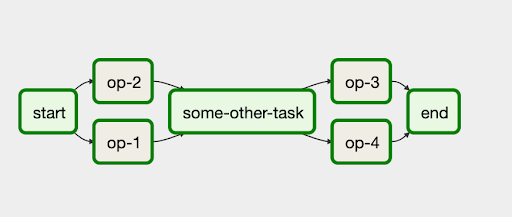
De esta forma, nos aseguramos de que los flujos tengan siempre un inicio y un final. Una de las ventajas de Airflow es que podemos definir condicionales para la ejecución de determinadas partes de grafo, permitiendo también poder unificar diferentes ramas una vez que se hayan cumplido determinadas acciones, como, por ejemplo, la finalización de las tareas previas.
Esto permite una enorme flexibilidad, siendo cada una de las tareas trozos de código que pueden desempeñar diferentes acciones a lo largo de un pipeline de datos.
Una tarea contiene el contexto de ejecución de un Operador. Dentro de Airflow tenemos una serie de operadores ya predefinidos, que nos permiten agilizar el desarrollo y nos abstraen de la implementación. Por ejemplo, tenemos el BashOperator para la ejecución de scripts en Bash o el PythonOperator para ejecutar programas en Python… Existen multitud de ellos, y también puedes crear operadores propios.
Una vez que tenemos las diferentes tareas que componen el DAG definidas, para finalizar nuestro DAG tenemos que definir su programación y planificación, es decir, indicar cuándo y cada cuánto se ejecuta ese flujo de datos.
Desde la interfaz podemos ver el estado y ejecución de cada uno de nuestros DAGs. Esta interfaz ofrece múltiples vistas desde donde podemos ver ejecuciones pasadas, logs que han dejado cada una de ellas, reejecutar partes de un DAG que han fallado o incluso evaluar tiempo de ejecución de cada uno de ellos.
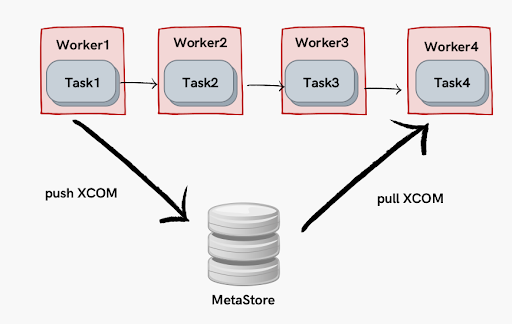
Una de las grandes ventajas de Airflow es que permite compartir información entre diferentes task mediante XComs. Así, podemos comunicar datos (de tamaño pequeño al estilo contraseñas, parametrizaciones, etc.) a lo largo de la ejecución del flujo.
Arquitectura Airflow
Pero, ¿cómo funciona Airflow por dentro? Principalmente Airflow consta de tres componentes:
- Airflow Database: Almacena y contiene la Metainformacion sobre los DAGs a ejecutarse y toda la información relativa a las ejecuciones y planificaciones de pipeline.
- Airflow Scheduler: Es el motor orquestador encargado de lanzar y ejecutar los pipelines, quien se encarga de lanzar las instancias y recursos necesarios para ejecutar un DAG.
- Airflow Webserver: Es el servidor web para presentar la información.
Para poder trabajar es necesario tener levantada la base de datos y Airflow Scheduler. Si bien puedes trabajar en modo command line con alguno de los comandos de Airflow la web te va a aportar más información y de forma más cómoda, por lo que se recomienda levantar los componentes.
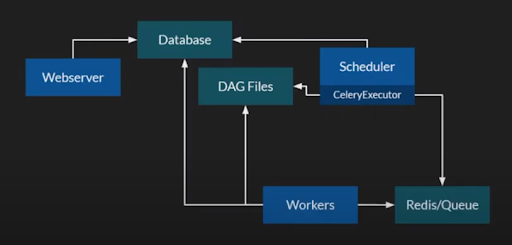
Dependiendo de cómo lo uses, si lo tienes instalado en una máquina o en kubernetes, o si incluso estás utilizando un sistema de colas Redis para encolar los trabajos, la gestión interna de Airflow trabaja principalmente leyendo la configuración del DAG. De esta forma, lanza el trabajo a los workers, ambos alimentan la base de datos con la información derivada de las ejecuciones y monitorización que posteriormente el webserver muestra en pantalla.
Mi primer DAG
Vamos adelante con nuestro primer DAG. Para crear un DAG realizaremos dos tareas muy sencillas, en el siguiente orden:
- Una task de DummyOperator (task de Airflow que no ejecutan acción)
- Una BashOperator que imprime por pantalla “Hola Mundo”
Lo primero que necesitamos es crear dentro de nuestro directorio de DAG un fichero Python “DagHolaMundo.py". Después, importamos las librerías de Airflow así como los operadores de task que vamos a utilizar:

A continuación debemos definir nuestro DAG, incluyendo el nombre, fecha de inicio en el que se comienza a ejecutar, fecha fin (si queremos que se detenga en algún momento) así como la frecuencia.
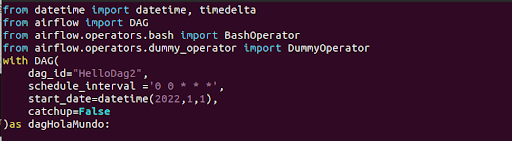
Una vez que inicie el DAG, este comenzará a ejecutar desde la fecha de inicio marcada con la frecuencia indicada. Esto nos permitirá ejecutar desde el “pasado” emulando la frecuencia diaria, por lo que, si ponemos una fecha del día 1 enero de inicio de DAG y hoy es 20 de enero, al arrancarlo el DAG intentará “ponerse al día con las ejecuciones” y reejecutará todas esas cargas seguidas. Si lo que queremos es que comience en el día actual en el que activamos el DAG, debemos pasarle el parámetro “catchup =False”.
Una vez definido el DAG procedemos a crear las tareas que los componen. Como habíamos indicado, tendremos dos task: un DummyOperator y un BashOperator para imprimir por pantalla:
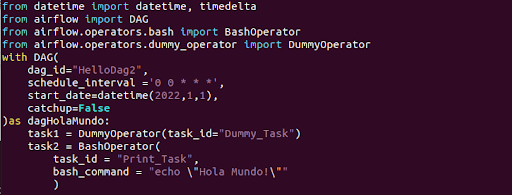
Como puedes observar, para la definición y creación de las task también hay que indicar un task_id, que posteriormente nos servirá para identificar y trazar dicha tarea.
Finalmente, nos queda establecer las relaciones entre las tareas. Como ya hemos dicho al principio de este artículo, en Airflow trabajamos con grafos dirigidos acíclicos, lo cual nos permite definir las relaciones y priorización entre tareas. De esta forma, utilizamos una sintaxis muy sencilla que indica que la tarea task1 se ejecuta antes que la task2:
:wq
¡Con esto tendríamos ya definido nuestro primer DAG! Veamos cómo se ve en el UI:
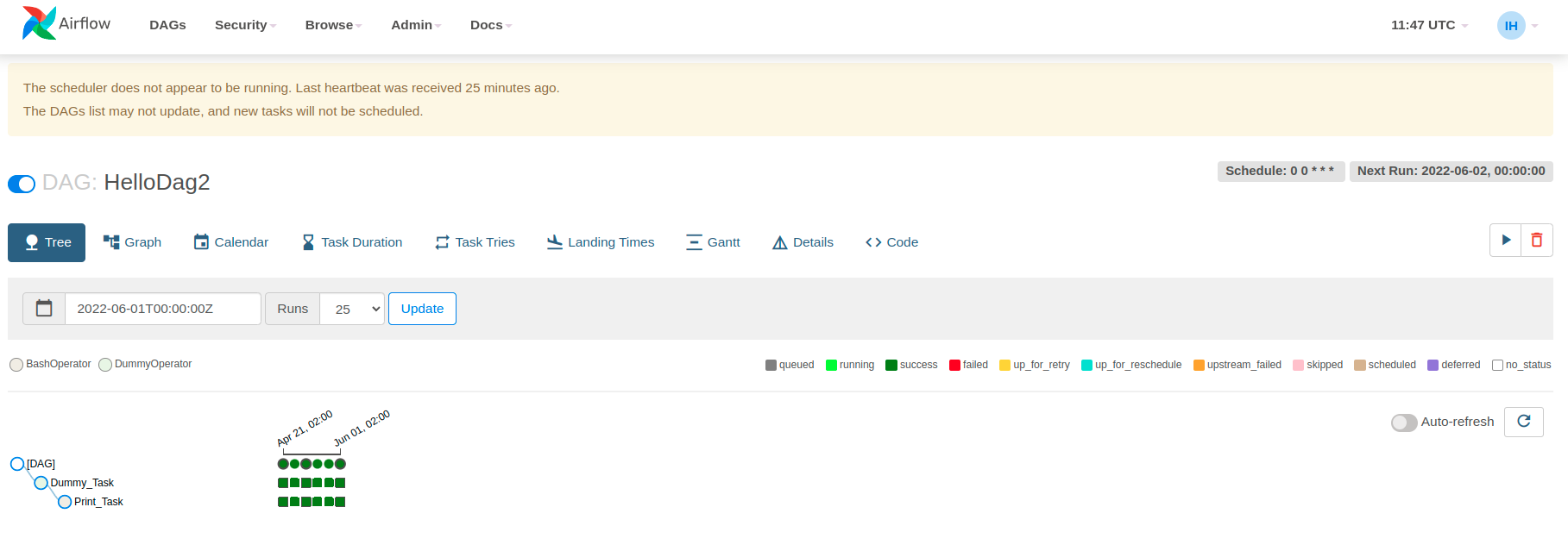
Podemos ver que al activar el DAG, comienza a ejecutarse y aparece en verde el resultado del mismo, por lo que si buscamos en los logs de las tareas podríamos ver el resultado:
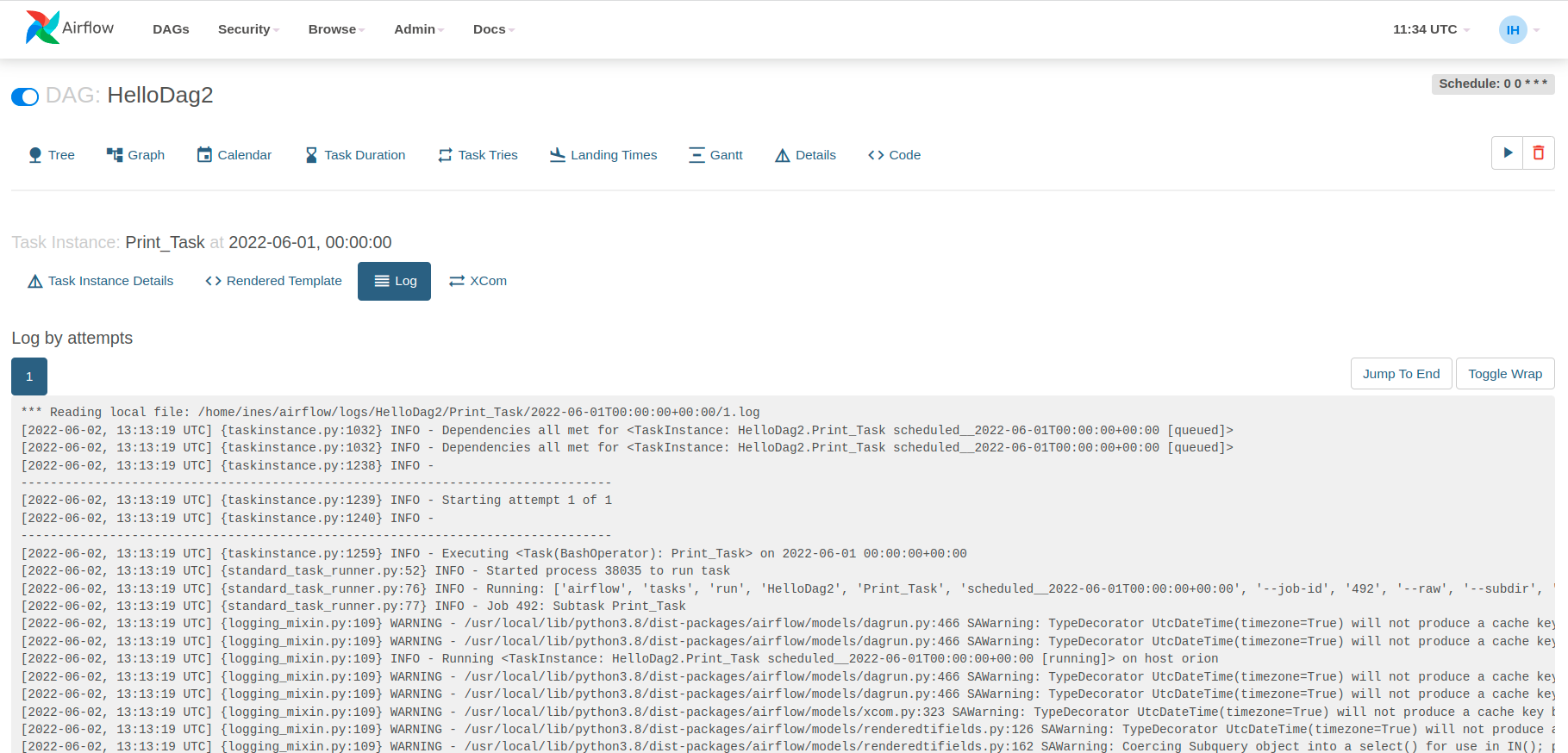
Así, observamos la ejecución en la captura anterior a partir de las ejecuciones de task2 y el log resultado de la misma.
¡Esto es sólo una pequeña prueba de todo lo que se puede hacer en Airflow! Este ejemplo ilustra la facilidad de uso y puesta en producción de DAG.
En resumen, podemos decir que Airflow consta de un gran potencial como herramienta para gestión de flujos en batch, permite una gran flexibilidad e integración con diversas fuentes, y permite tener todos tus flujos en un mismo sitio monitorizados.
¡Una gran herramienta para poder gestionar todas tus pipelines!
Este post ha sido elaborado desde la capacidad de Data & IA.

