
Cada vez son más las organizaciones que están trasladando sus sistemas desde arquitecturas formadas por Data Warehouses y Data Lakes a arquitecturas compuestas por un Data Lakehouse.
Mientras que los Data Lakes y los Data Warehouses son comúnmente utilizados para almacenar y analizar datos estructurados, un Data Lakehouse es una tercera forma eficiente de almacenar y analizar datos que unifica las dos arquitecturas al tiempo que preserva los beneficios de ambas. Un Data Lakehouse, por tanto, permite a las organizaciones obtener lo mejor de ambos mundos.
En este post se resume y se da contexto histórico a la evolución que este tipo de arquitecturas han sufrido, y qué forma y ventajas ofrece un Data Lakehouse.
Por último, se hablará de Databricks, una plataforma de procesamiento de datos que cuenta con las características necesarias para la formación de un Data Lakehouse, y que resulta especialmente útil para el despliegue y desarrollo de proyectos avanzados de inteligencia artificial (IA) y aprendizaje automático (ML).
Data Warehouse y el Data Lake
Con el surgimiento de las aplicaciones Web y los sistemas OLTP, uno de los problemas más comunes relacionado con los datos cambió de ‘el no ser capaz de encontrar los datos’ a ‘no ser capaz de encontrar los datos correctos’. La demanda de nuevas aplicaciones que satisficieran las necesidades dentro de las distintas áreas y departamentos de la organización, originó el desarrollo y despliegue de sistemas independientes. Esta división dio lugar a problemas de integridad, al no contar con una única fuente de verdad, siendo común que se duplicarán funciones o modelos entre las aplicaciones y se almacenasen el mismo dato en diferentes puntos e incluso con valores distintos. La necesidad de contar con datos veraces sobre los que tomar decisiones provocó la creación de los Data Warehouses.
Un Data Warehouse recopila datos de múltiples fuentes en una única ubicación independiente, contando además con una infraestructura analítica alrededor (metadatos, modelos relacionales optimizados, data lineage, etc). Se trata de sistemas costosos, con alta disponibilidad y velocidad de acceso.
Los Data Warehouses abrieron las puertas del procesamiento analítico. El pasado se convirtió en un gran predictor del futuro.
El almacenamiento de datos históricos y su análisis pronto comenzó a tener un gran valor. Por otro lado, los Data Warehouses estaban diseñados para la generación de reportes y el BI, el tratamiento de datos estructurados y basados en transacciones. La evolución tecnológica siguió su curso descubriéndose limitaciones en los Data Warehouses clásicos.
Se incrementó la generación de datos de texto, IoT, imágenes, audio, etc. Datos no estructurados y de gran volumen junto al alzamiento de nuevas tecnologías de análisis y predicción, como son la Inteligencia Artificial y el Machine Learning, donde se requieren el uso de datos no basados en SQL para muchos de sus algoritmos.
El desarrollo de nuevos métodos de análisis que requieren del procesamiento de datos, pueden ser más experimentales en una infraestructura compartida donde dan como resultado una competencia por el acceso a los recursos de la arquitectura. Además, interfieren en la generación de los reportes de negocio y la necesidad de duplicar datos.
Con la finalidad de almacenar todos los datos generados por una organización, surgen los Data Lakes, capaces de almacenar grandes volúmenes de datos en brutos, con la esperanza de que, llegado el momento, si esos datos son necesarios, bastaría únicamente con indagar dentro del Data Lake y, una vez encontrados, cogerlos y manipularlos.
Rápidamente se descubrió que usar los datos de un Data Lake no es tan sencillo por las siguientes razones:
-
Dependiendo del tipo de usuario sus necesidades son completamente distintas. Por ejemplo, un usuario de negocio frente a un científico de datos.
- El gran volumen de datos almacenado dificulta diferenciar qué datos son útiles de los que no.
- Al guardar los datos en bruto no se incluyen metadatos de los mismos.
-
Problemas para saber si se tratan de datos actualizados o saber cuán precisos y veraces son.
La falta de gobernanza en los datos y de optimización en los procesos ha dado lugar a que muchos de los Data Lakes actuales no hayan sido exitosos.
Paradigma actual
En la actualidad, la mayoría de las organizaciones han adoptado arquitecturas en las que es muy común encontrarse con el uso de múltiples sistemas de análisis, incluyendo uno o varios Data Warehouses, Data Marts, un Data Lake y otros sistemas especializados.
Los principales problemas de este tipo de arquitecturas son:
- Costes, por el movimiento de datos entre sistemas. Los Data Lakes están preparados para poder almacenar un alto volumen de datos a bajo precio, pero no cuentan con capacidad de procesamiento. Para superar la falta de rendimiento y refinar la calidad de los datos, se utilizan ETL (Extract/Transform/Load) para copiar un subconjunto de los datos del Data Lake a un Data Warehouse. Esta arquitectura dual requiere de sistemas de ETLs y ELTs, donde se corre el riesgo de introducir errores al transformar los datos, mantener la coherencia entre el Data Lake y el Data Warehouse es un proceso tedioso y costoso.
- Dificultad para intercambiar información entre sistemas. Los Data Warehouses usan formatos propios que provocan costes adicionales a la hora de migrar datos y flujos de trabajo. En general, es habitual que únicamente se permita el acceso mediante SQL, complicando ejecutar otros sistemas de análisis como el Machine Learning. En la actualidad y a pesar de los esfuerzos realizados, la mayoría de los sistemas líderes de Machine Learning (TensorFlow, PyTorch y XGBoost) tienen problemas de integración al montarse sobre un Data Warehouse.
Data Lakehouse
Partiendo desde los Data Lakes, emerge un nuevo tipo de arquitectura llamado el Data Lakehouse, que busca solucionar los problemas anteriormente mencionados fusionando las principales ventajas de los Data Lakes y los Data Warehouses.
Un Data Lakehouse debe ser capaz de almacenar información estructurada y no estructurada, contar con características de gestión similares a las de un Data Warehouse y operar directamente en los sistemas de almacenamiento de bajo coste usados en los Data Lakes.
Las características que ha de conseguir un Data Lakehouse son las siguientes:
-
Apoyarse en un Data Lake. Almacenar todo tipo de información en sistemas de almacenamiento de bajo coste, como Amazon S3, Azure Blob Storage o Google Cloud.
- Aportar calidad y fiabilidad a los datos almacenados. Implantar sistemas que garanticen la coherencia de los datos cuando se escriban o lean, desde varias fuentes y de manera simultánea.
- El uso de catálogos y esquemas aportando mecanismos de gobernanza y auditoría. Permitir DML mediante múltiples lenguajes, almacenar historiales de registros sobre los cambios realizados y los datos. Además de generar snapshots de los datos y controles de acceso basado en roles.
- El uso de técnicas que optimicen el rendimiento y permitan el escalado.
- Soporte para que herramientas de BI trabajen directamente sobre la fuente de los datos, reduciendo latencias y costes al no tener que mantener dos copias tanto en Data Lake como en el Warehouse.
- Permitir el uso de datos no estructurados y no-SQL.
- Facilitar el intercambio de información entre plataformas, haciendo uso de formatos de código abierto como parquet y ORC, ofreciendo APIs para el acceso eficiente a los datos.
- End-to-end streaming. La compatibilidad con aplicaciones en tiempo real elimina la necesidad de contar con sistemas dedicados para este.
-
Procesamiento masivo en paralelo y soportar diversas cargas de trabajo y de análisis.
En la actualidad, los grandes proveedores de computación en la nube cuentan con sus propias soluciones con patrones similares a los de un Lakehouse, BigQuery de Google, Redshift Spectrum de Amazon o Azure Synapse Analytics de Microsoft son algunos de los ejemplos. Estas soluciones se centran principalmente en Lakehouse y otras aplicaciones SQL.
En la siguiente imagen se muestra de forma esquemática las diferentes características de cada arquitectura. Data Warehouse / Data Lake / Data Lakehouse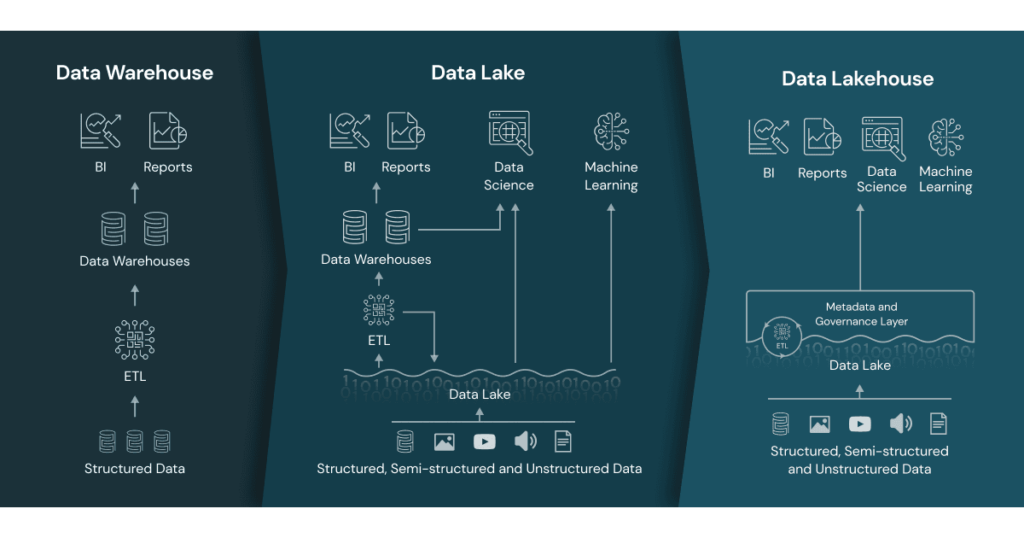
Databricks: Data Lakehouse
Databricks es una plataforma de procesamiento de datos. La empresa se fundó en 2013 con los creadores y los desarrolladores principales de Spark. Permite hacer analítica Big Data e Inteligencia Artificial de una forma sencilla y colaborativa, permitiendo flujos de trabajo no limitados al BI.
Además, contiene muchas funcionalidades que la hacen una solución analítica bastante completa, permitiendo fusionar todos los procesamientos de datos en un único sistema, lo que significa que los desarrollos y gestión de pipelines sean más rápidos y cómodos, sin necesidad de acceder a varios sistemas.
Databricks cuenta con las herramientas necesarias para convertirse en el sistema central de análisis de una gran corporación. Sin embargo, es importante destacar que no es autosuficiente, siempre ha de contar con un sistema externo (Data Lake, aplicaciones externas, Data Marts).
En la siguiente imagen se muestra el ecosistema de Databricks en Microsoft Azure donde se ejemplifica lo anteriormente mencionado. Databricks en Microsoft Azure.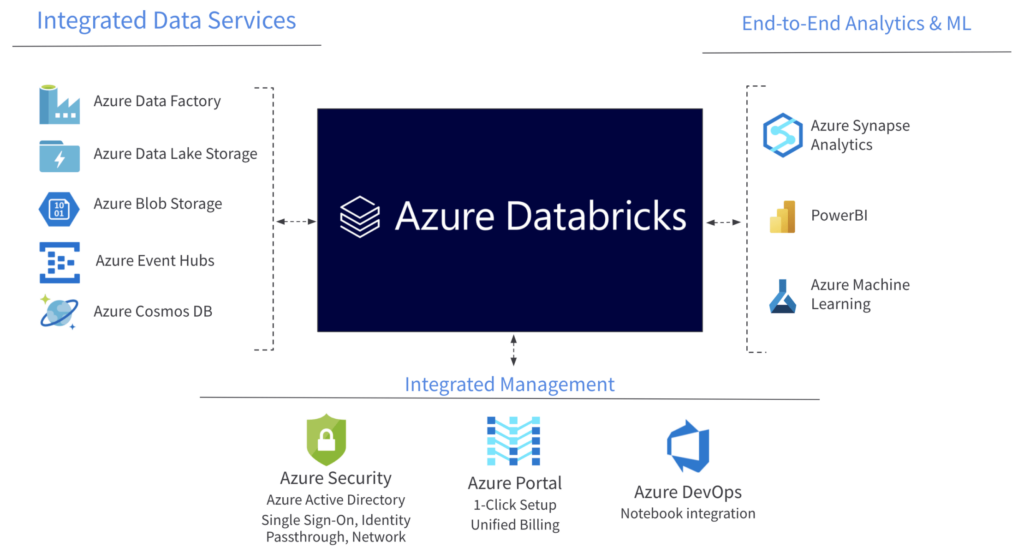
El núcleo de la plataforma Databricks se compone de tres herramientas de código abierto:
-
Apache Spark. El núcleo de Databricks es Spark. Apache Spark es un framework de programación para procesar datos masivos o Big Data, de forma distribuida, diseñado para ser rápido. Aunque está programado en Scala, cuenta con varias APIs que hacen posible su uso mediante lenguajes de programación como R, SQL, Python y Java. Cuenta con su propio optimizador de querys “Catalyst”, generando un plan de operaciones lógico y un plan físico para la gestión de recursos. Permite tanto el procesamiento bach como streaming, y es capaz de escalar horizontalmente procesados con Pandas, mediante la librería externa Koalas, o de manera nativa desde con la API de Pandas en Spark, que está disponible a partir de Apache Spark 3.2.
-
Delta Lake. Se ejecuta sobre un Data Lake proporcionando transacciones ACID, metadatos y unifica el procesamiento de datos en flujo y por lotes, la aplicación de esquemas y el versionado de datos.
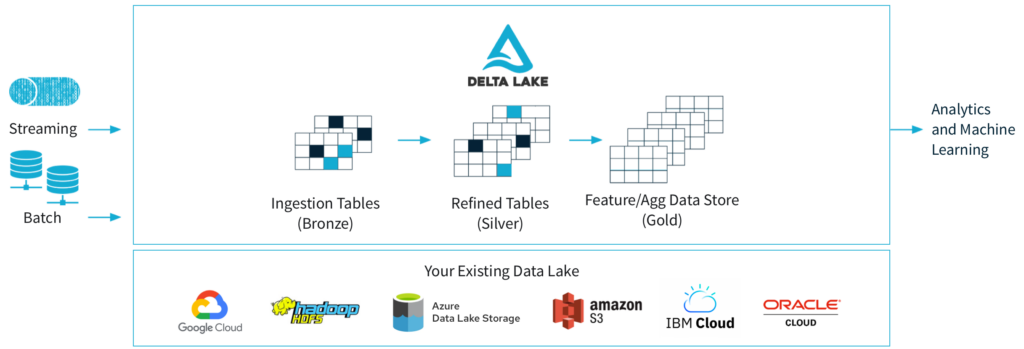
Delta Lake
-
MLFlow: Es una plataforma de código abierto para administrar el ciclo de vida completo del aprendizaje automático.
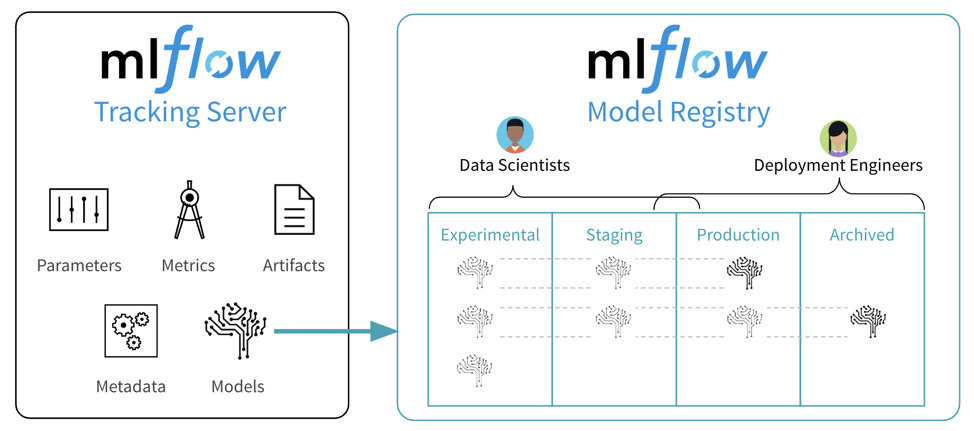
ML Flow
En la siguiente captura se muestra a grandes rasgos como gracias a estas herramientas de código abierto, Databricks se convierte en una plataforma donde la ingeniería de datos, el Machine Learning y la ciencia de datos conviven de manera colaborativa.
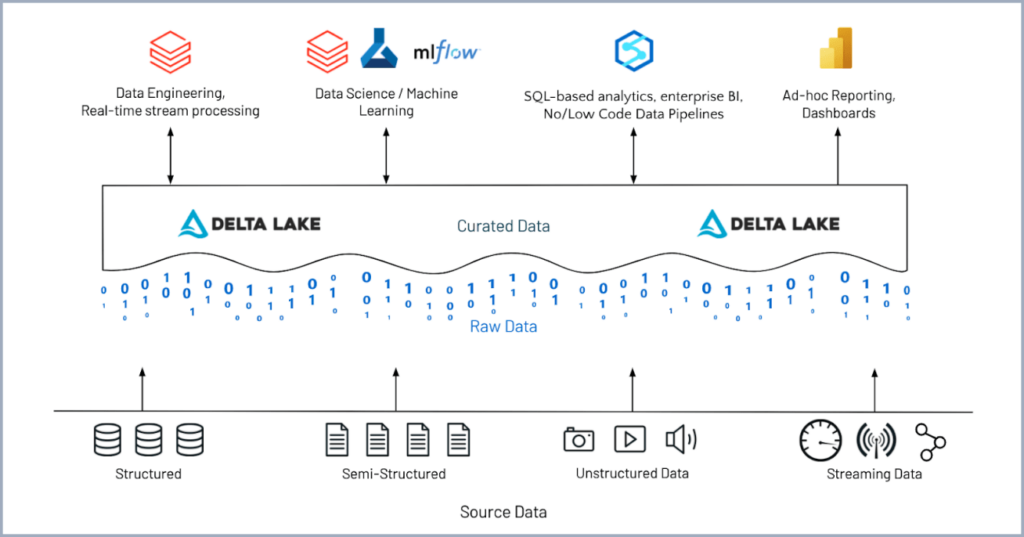
Herramientas Open Source
Herramientas Open Source
Debido a una interfaz gráfica llamada el Workspace de Databricks, un servicio SaaS que permite acceder a todos los activos de Databricks. El Workspace organiza los objetos (blocs de notas, bibliotecas y experimentos) en carpetas y proporciona un acceso cómodo e intuitivo a los diferentes recursos y datos.

