

Hoy en día las grandes empresas que han encontrado valor en sus datos están llegando a estados de madurez en los que es necesario profundizar y profesionalizar la gestión de los modelos y su entrenamiento.
Monitorizar y evaluar el reentrenamiento de un modelo de aprendizaje automático puede ser una tarea costosa y en la actualidad existen algunas herramientas que pueden ayudarnos a gestionar de mejor manera el ciclo de vida de un modelo analítico.
El ciclo de vida de un modelo de datos pasa desde las primeras etapas de identificación de fuentes, limpieza y procesado de datos para generar un primer modelo. Este modelo es muy probable que queramos ponerlo en producción para poder consumirlo de forma automática, pero aquí no acaba el ciclo de vida. Con el tiempo, queremos actualizar nuestro modelo con los nuevos datos que tenemos, y queremos también hacerlo de forma automática y lo más integrada posible. Además, deberíamos monitorizar todo este flujo y métricas de nuestros algoritmos por diversos motivos: autoría, gestión de cambios, etc.
.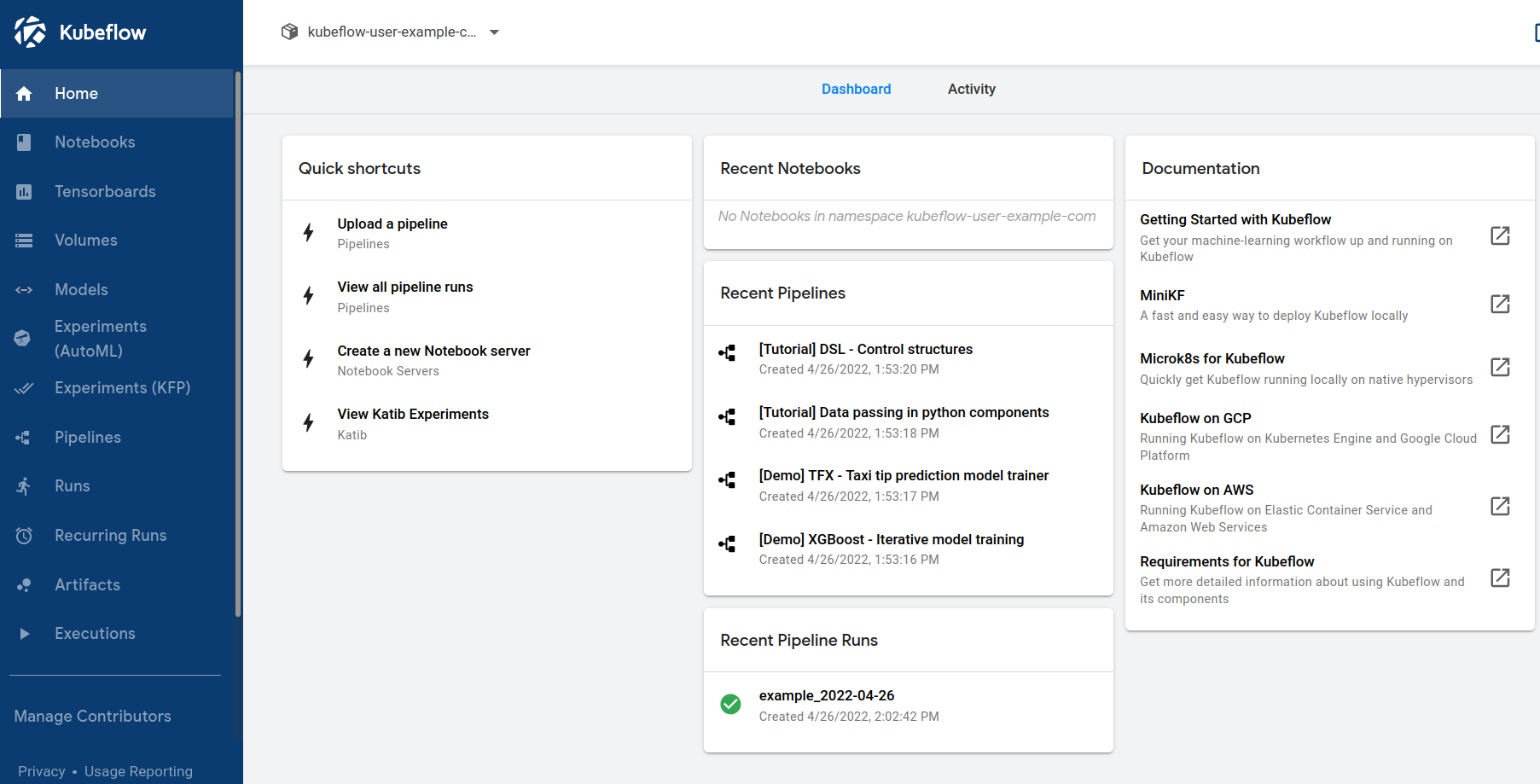
Kubeflow una herramienta para poder desplegar modelos de machine learning sobre kubernetes de una manera sencilla. Tiene diferentes componentes para cada estado del ciclo de vida del modelo: exploración, training y despliegue.
Estos componentes son:
- Notebooks: Permitiendo crear y manejar de forma interactiva Jupyter Notebooks.
- Pipelines: Para construir y desplegar workflows portables y escalables de machine learning.
- Training Operators: Para entrenar los modelos con diferentes Frameworks.
- KServe: Para servir modelos en el clúster de forma escalable.
Al ser Kubeflow una de las principales herramientas en mercado para poder desplegar un ciclo del dato supervisado de una forma sencilla, vamos a contar los primeros pasos para poder desplegar uno de los principales componentes de Kubeflow, Kubeflow Pipelines.
¿Qué es Kubeflow?
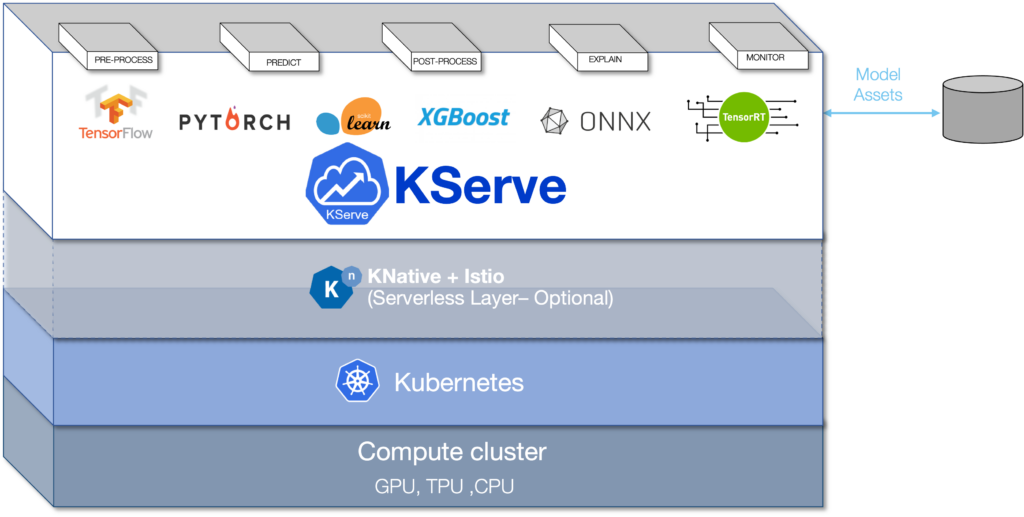
Una de las plataformas más usadas para la automatización de procesos es Kubeflow Pipelines, un componente del proyecto Kubeflow, pensado para poner en producción aplicaciones de machine learning de forma sencilla. Como parte de este proyecto, Kubeflow Pipelines es excelente para flujos de trabajo relacionados con el entrenamiento, evaluación y mejora continua de modelos de machine learning. Podemos interactuar fácilmente con otros componentes como KServe, para entrenar modelos con computación distribuida e independiente del framework de machine learning o Katib, para el ajuste automático de hiperparámetros. Sin embargo, no hay razón para no hacer un uso más general de Kubeflow Pipelines, ya que su arquitectura nos permite llevar a cabo una gran variedad de tareas.
Deployment
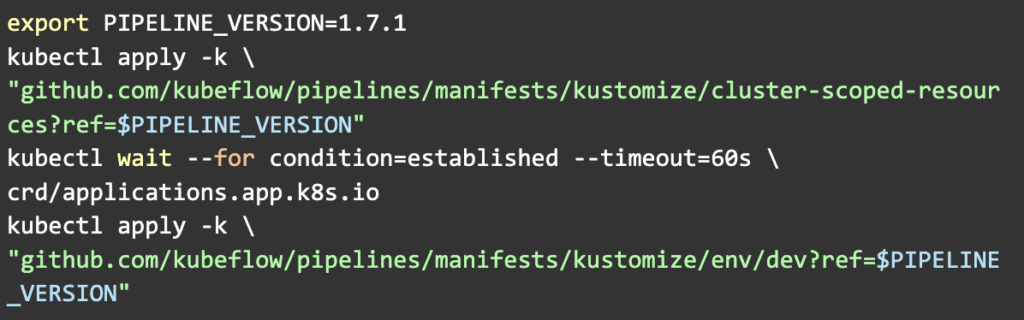
Para usar Kubeflow Pipelines tenemos que habilitar un cluster de Kubernetes (K8s), ya sea simulado en nuestro dispositivo o mediante los servicios de un proveedor como Google (Google Cloud) o Amazon (AWS). Normalmente, si estamos desarrollando una aplicación, usaremos la primera opción y, cuando estemos listos para su despliegue, pasaremos a la segunda. Si no se ha trabajado con K8s necesitaremos un periodo de adaptación, pero por otra parte, una vez que nos hayamos habituado el paso de desarrollo a producción es sencillo. K8s es en gran medida independiente de la infraestructura en la que se encuentra su cluster (cloud agnostic), de hecho, podemos desplegar Kubeflow Pipelines en cualquier clúster con el mismo comando:
Pipelines, runs, steps y experiments
Una vez hemos desplegado Kubeflow Pipelines podemos acceder a su interfaz gráfica, desde la cual se nos introducirá a los principales conceptos de su funcionamiento.
Todo proceso que queramos automatizar se puede dividir en pasos. Cada paso o componente puede tener otros que le preceden, que le siguen o que se pueden ejecutar a la vez. En Kubeflow la descripción de estos componentes y sus relaciones se conoce como pipeline. Podemos importar pipelines mediante ficheros YAML y ver un esquema de su descripción en la interfaz gráfica:
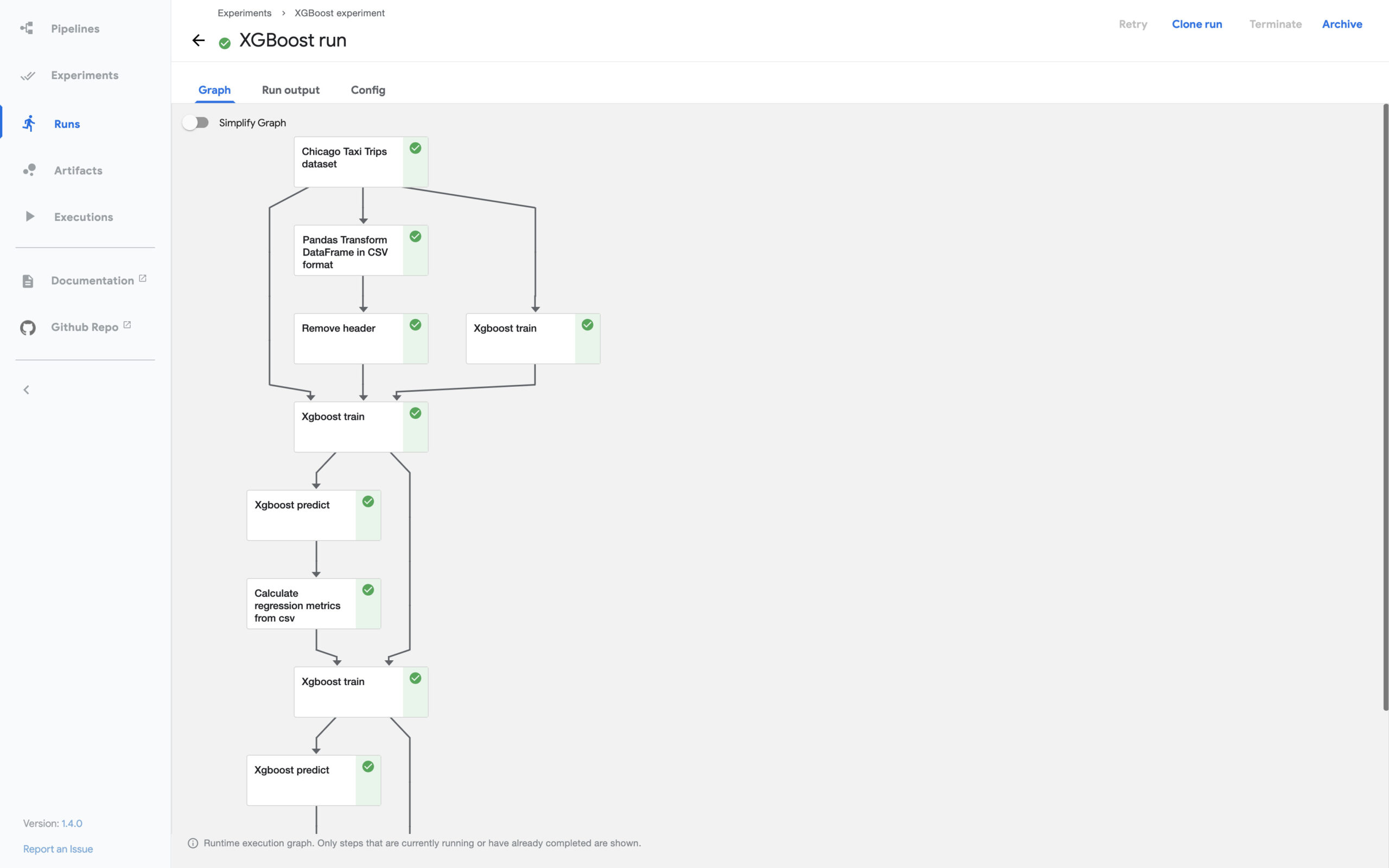
Cada vez que ejecutamos las instrucciones de una pipeline en nuestro cluster, Kubeflow Pipelines crea una run. Toda la información de las runs queda registrada en el almacén de artefactos de Kubeflow (otro servicio que se despliega en K8s), desde la interfaz gráfica podemos visualizar el estado de una run y de la ejecuciones de cada uno de los componentes, a lo que Kubeflow Pipelines se refiere como steps.
Es posible crear runs de forma periódica, manual o activarlas mediante código como veremos al final del artículo.
Por último, Kubeflow Pipelines ofrece la posibilidad de organizar de forma lógica las runs mediante experimentos, por ejemplo podemos crear una experimento donde probamos una pipeline con diferentes configuraciones.
Para aprender más sobre estos conceptos se puede revisar la documentación de Kubeflow Pipelines.
Crear componentes y pipelines
Cada uno de los componentes dentro de un pipeline está escrito en Python y se ejecuta dentro de un contenedor de Docker que se despliega dentro de un pod de nuestro cluster de Kubernetes. Los contenedores proporcionan aislamiento y evitan problemas de compatibilidad con los diferentes módulos a instalar para cada componente a la vez que permiten controlar las entradas y las salidas.
Este funcionamiento hace que haya ciertas reglas a la hora de crear el código para los componentes y para organizarlos en un pipeline. Kubeflow Pipelines pone a nuestra disposición varios métodos que usaremos según nuestras preferencias.
Podemos crear componentes con dependencias sencillas que no queramos volver a utilizar directamente de funciones de Python. Mientras que, si tenemos componentes reutilizables con contenedores personalizados o simplemente queremos más control de nuestros componentes podemos escribir una especificación.
Combinando estos métodos podemos escribir componentes personalizados en el mismo script de nuestra pipeline mientras que importamos otros reutilizables de nuestros archivos o un repositorio remoto.
Para construir una pipeline tan solo hay que conectar las salidas de unos componentes con las entradas de otros, dentro de una función de Python, que después podemos compilar en el fichero YAML que importamos desde la interfaz gráfica:
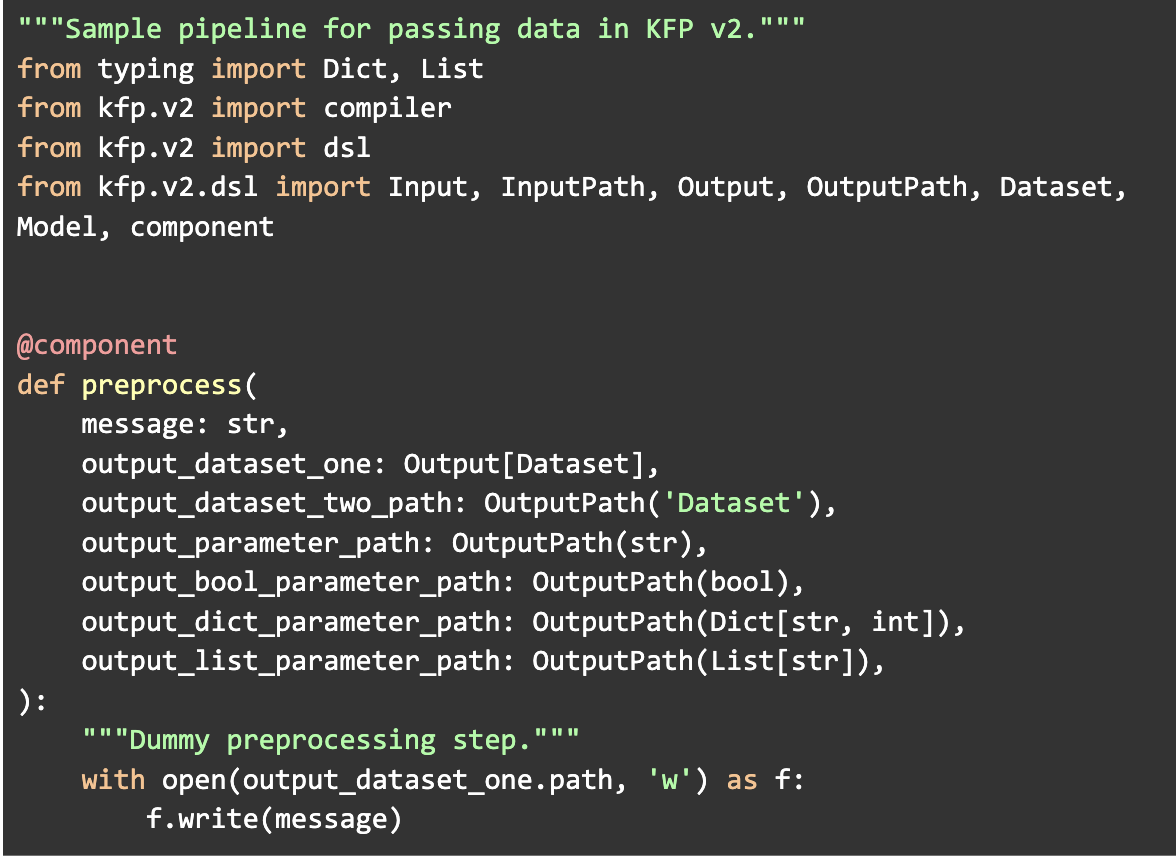
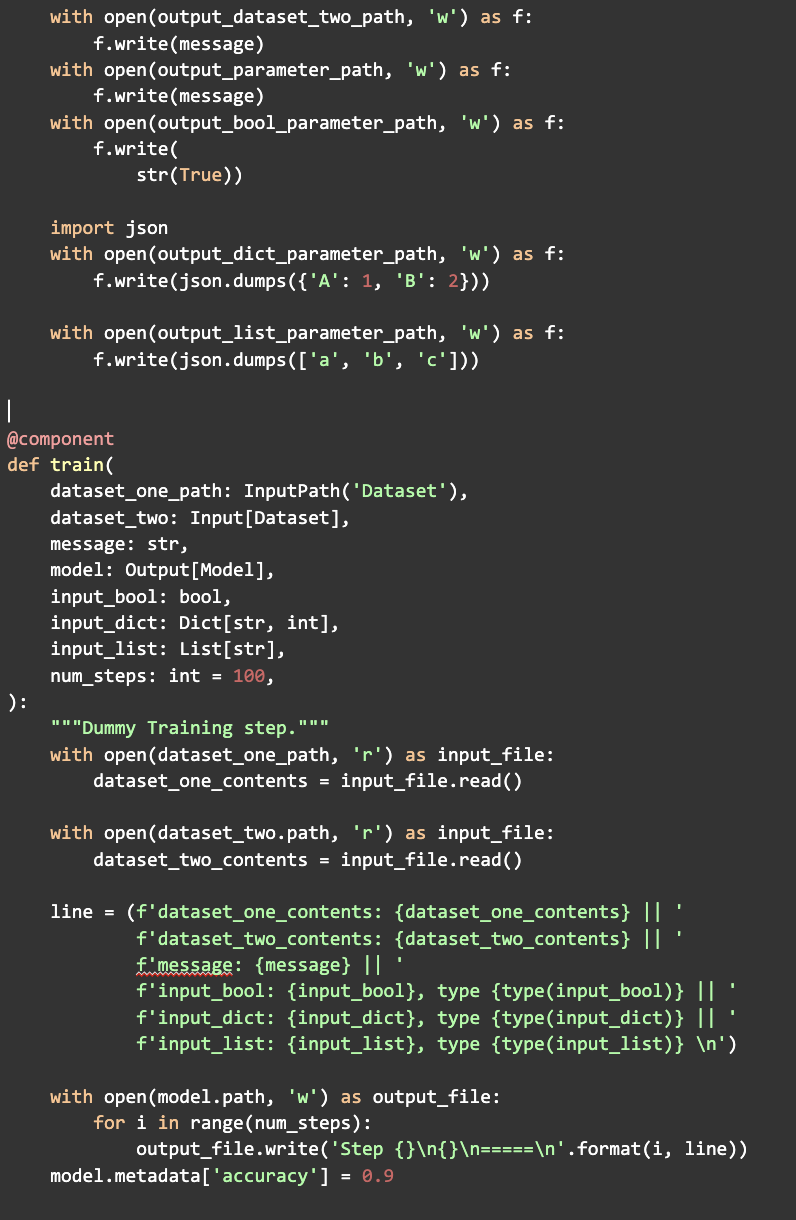
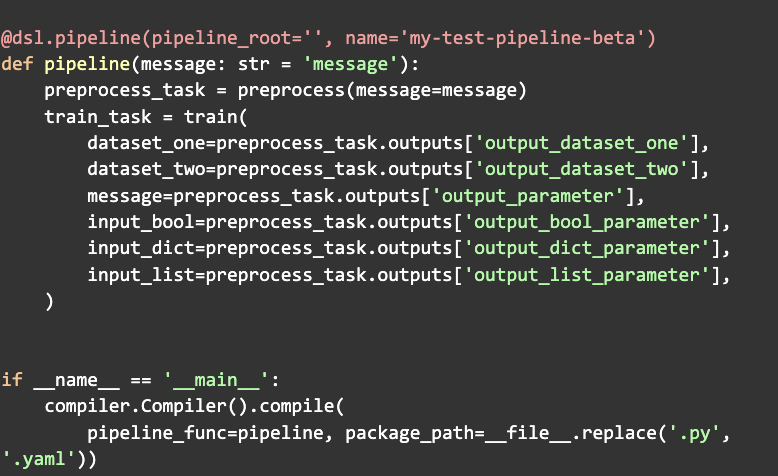
Repositorio de Artefactos
Kubeflow Pipelines usa un repositorio de artefactos para guardar las pipelines importadas (así no se tienen que compilar más de una vez) y toda la información generada en las runs.
Desde la interfaz gráfica del repositorio podemos consultar información de los artefactos de entrada y salida de cada step de nuestra run para monitorizar nuestra pipeline.
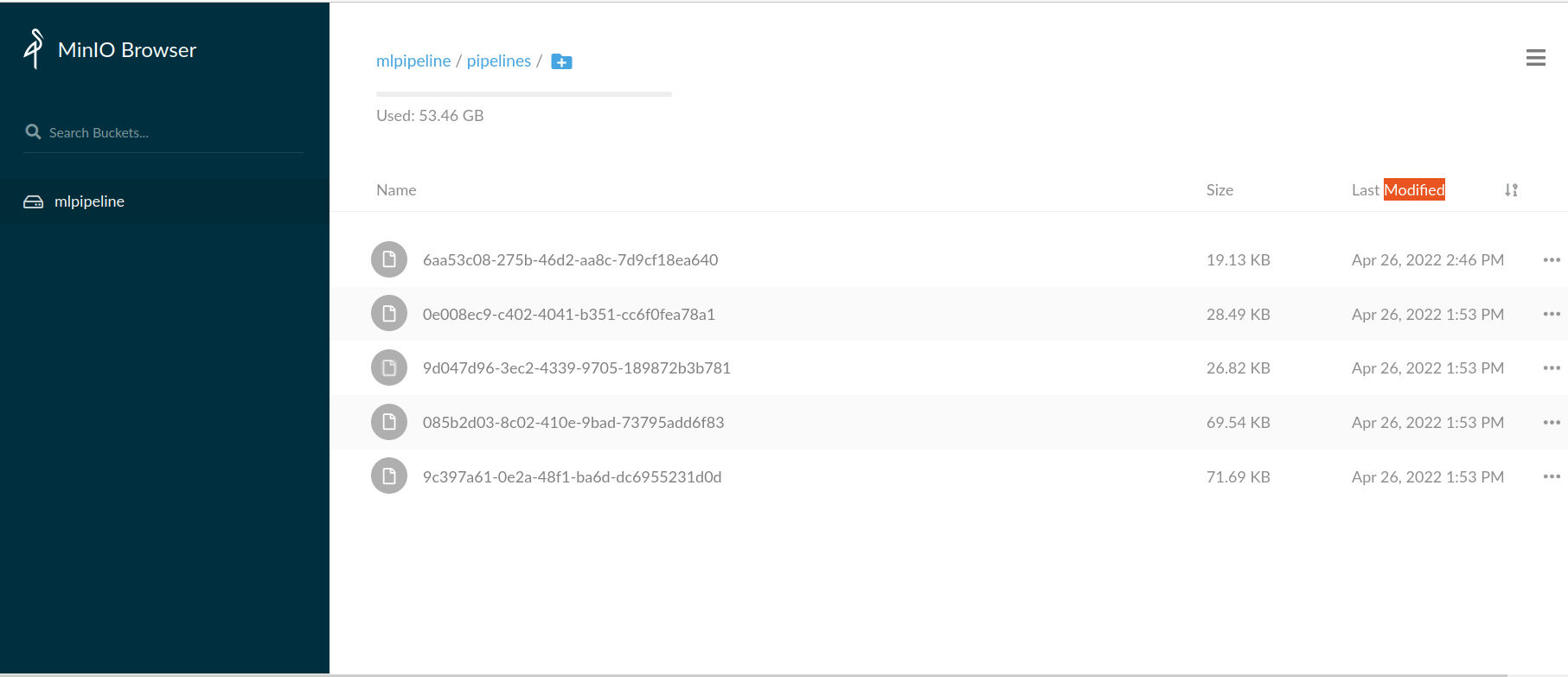
De forma predeterminada, Kubeflow almacenará los artefactos en MinIO, un repositorio de artefactos nativo de Kubernetes, pero este se puede cambiar en cada pipeline modificando su pipeline root.
Cliente de Kubeflow Pipelines
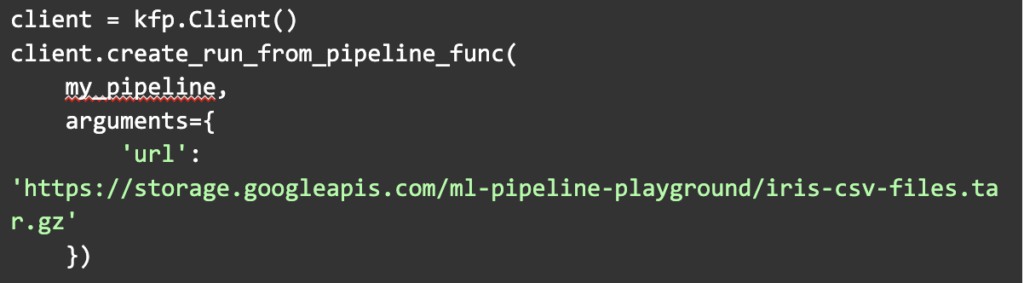
El cliente de Kubeflow nos abre un mundo de posibilidades de automatización que nos son viables desde la interfaz gráfica.
Por ejemplo, activar runs de forma condicionada desde nuestro código de Python:
También podemos ver de forma automática toda la información de una run con:

Entre esta información se encuentran los artefactos de entrada y salida de cada uno de los pasos, por tanto, podemos descargarlos y monitorearlos automáticamente.

