
Por Mariya Pomitun
Hilos Virtuales vs Hilos Tradicionales: Un Análisis de Rendimiento en Java 21
En el entorno empresarial actual, donde la demanda de servicios digitales crece de forma exponencial, la capacidad de una aplicación para gestionar eficientemente miles de solicitudes concurrentes se convierte en un factor competitivo clave.
Esto es especialmente relevante en sectores como el comercio electrónico, la banca en línea y las plataformas de reserva de viajes, donde los picos de tráfico pueden ocurrir en cualquier momento.
Introducción
La adopción de hilos virtuales en Java 21 ofrece una oportunidad para escalar con mayor eficiencia, optimizando el uso de recursos y mejorando la capacidad de respuesta del sistema. Esto, a su vez, se traduce en una mejor experiencia para el usuario final, mayor retención de clientes y un impacto positivo en los resultados del negocio.
Este artículo explora el potencial de los Hilos Virtuales, los compara con los hilos tradicionales y presenta experimentos prácticos usando un sistema de reservas de vuelos.
La relación entre los hilos y el rendimiento en las aplicaciones
Para entender cómo los hilos virtuales pueden impactar el rendimiento de las aplicaciones, especialmente en escenarios de alta concurrencia, es esencial comprender primero la relación entre los hilos y el rendimiento (throughput) en una aplicación típica de Java.
Consideremos una aplicación web de Spring Boot utilizando el servidor Tomcat, que está configurado por defecto con 200 hilos. Cada hilo es responsable de procesar una solicitud. Si cada solicitud tarda un segundo en procesarse, la aplicación podrá manejar 200 solicitudes por segundo, que es el rendimiento de la aplicación.
Si necesitamos procesar más solicitudes concurrentemente, intuitivamente pensaríamos que agregar más hilos haría que la aplicación se escalara. Sin embargo, los hilos son recursos a nivel de sistema operativo que consumen memoria y poder de cómputo. Esto crea varios desafíos:
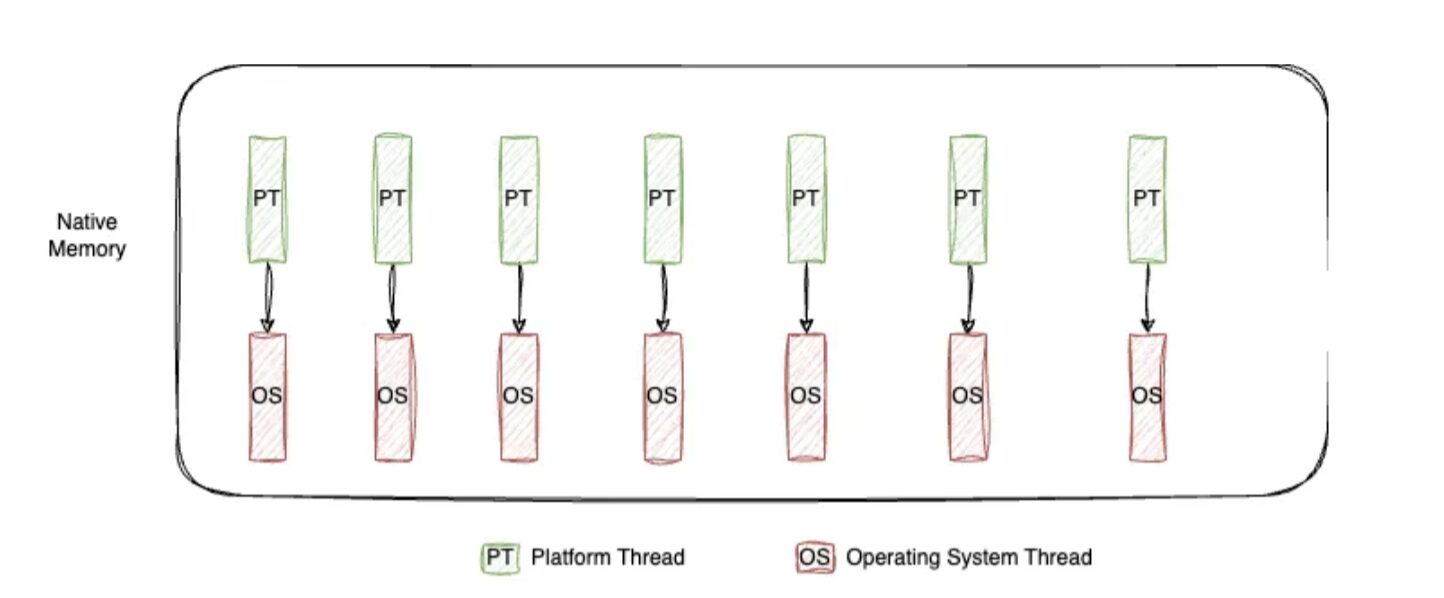
· Límites de Recursos: Los hilos a nivel de sistema operativo están limitados por los recursos del sistema, como la memoria. Si se crean demasiados hilos, el sistema podría quedarse sin recursos o alcanzar los límites de creación de hilos, lo que podría generar errores como OutOfMemoryError.
· Hilos Inactivos: En las arquitecturas modernas basadas en microservicios, los hilos a menudo permanecen inactivos mientras esperan respuestas de llamadas de red o servicios externos. A pesar de estar inactivos, estos hilos siguen consumiendo recursos del sistema.
· Sobrecarga de Hilos: Cada hilo requiere una pila dedicada, y a medida que aumenta el número de hilos, también lo hace la sobrecarga del sistema. Eventualmente, agregar más hilos lleva a rendimientos decrecientes, ya que los beneficios de una mayor concurrencia se ven superados por los recursos necesarios para gestionar los hilos.
Esta ineficiencia inherente de los hilos tradicionales crea barreras para la escalabilidad en aplicaciones de alta concurrencia. Aquí es donde los hilos virtuales pueden ofrecer una alternativa más eficiente, la cual exploraremos más a fondo en la siguiente sección.
Hilos Virtuales: Una Solución para la Escalabilidad de Hilos
Los hilos virtuales no son hilos tradicionales del sistema operativo, lo que significa que no se crean ni se gestionan a nivel de sistema operativo. En su lugar, son como pequeños objetos creados en el heap, y su ejecución está gestionada por la JVM.
Esto permite que los hilos virtuales sean mucho más ligeros en comparación con los hilos tradicionales. Esta distinción permite la creación de millones de hilos virtuales sin alcanzar los límites de creación de hilos del sistema operativo. Esto permite que las aplicaciones se escalen de manera eficiente con alta concurrencia, sin los cuellos de botella tradicionales.
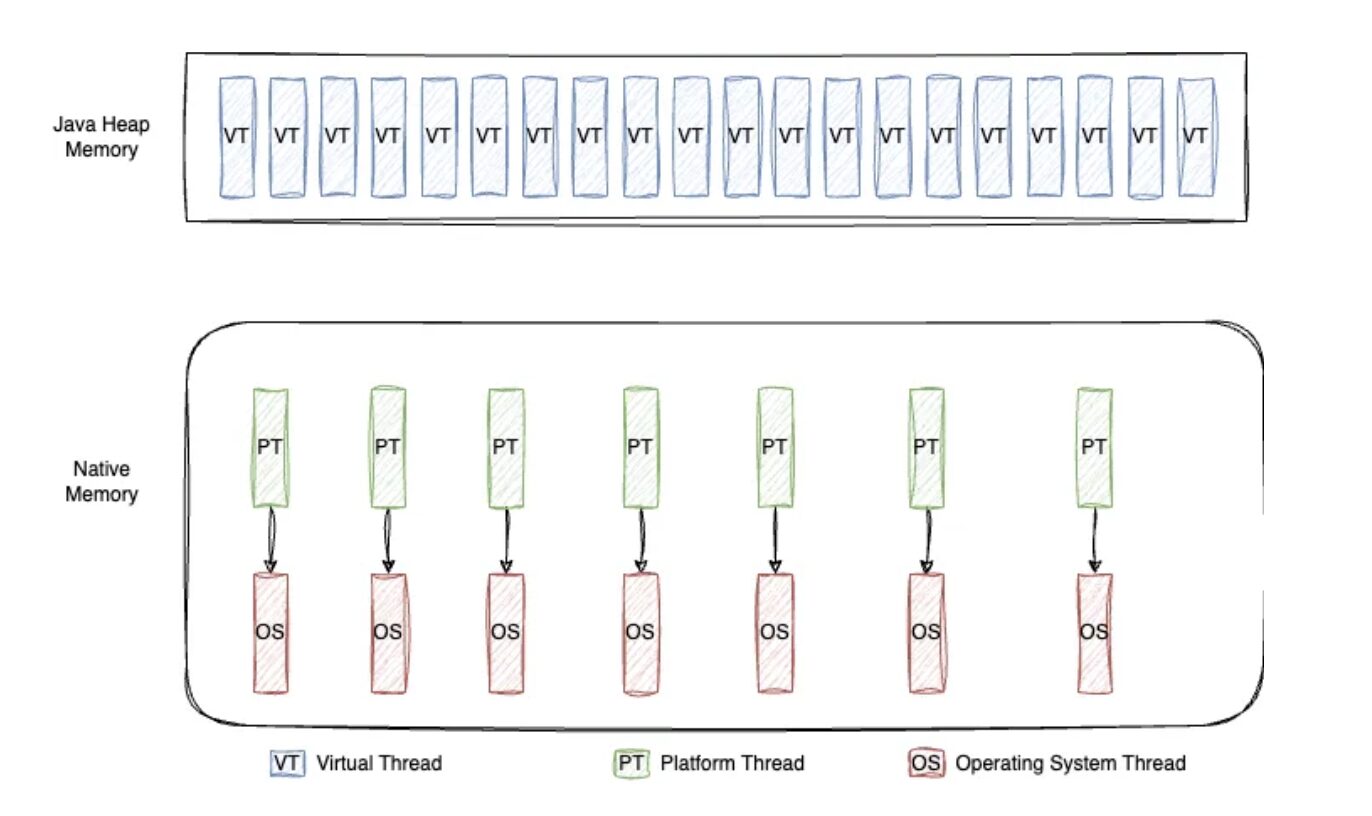
Así es como funciona el proceso:
Cuando llamas a thread.start() en un hilo virtual, este se agrega a la cola de ForkJoinPool, que se utiliza para la programación de tareas. El número de hilos de plataforma (hilos del sistema operativo) en el ForkJoinPool depende del número de procesadores (núcleos de CPU) disponibles en la máquina. Estos hilos de plataforma toman las tareas de la cola y comienzan a ejecutarlas. Este proceso se llama "montar"; un hilo virtual en un hilo de carrera. Un hilo de carrera solo puede ejecutar un hilo virtual a la vez.
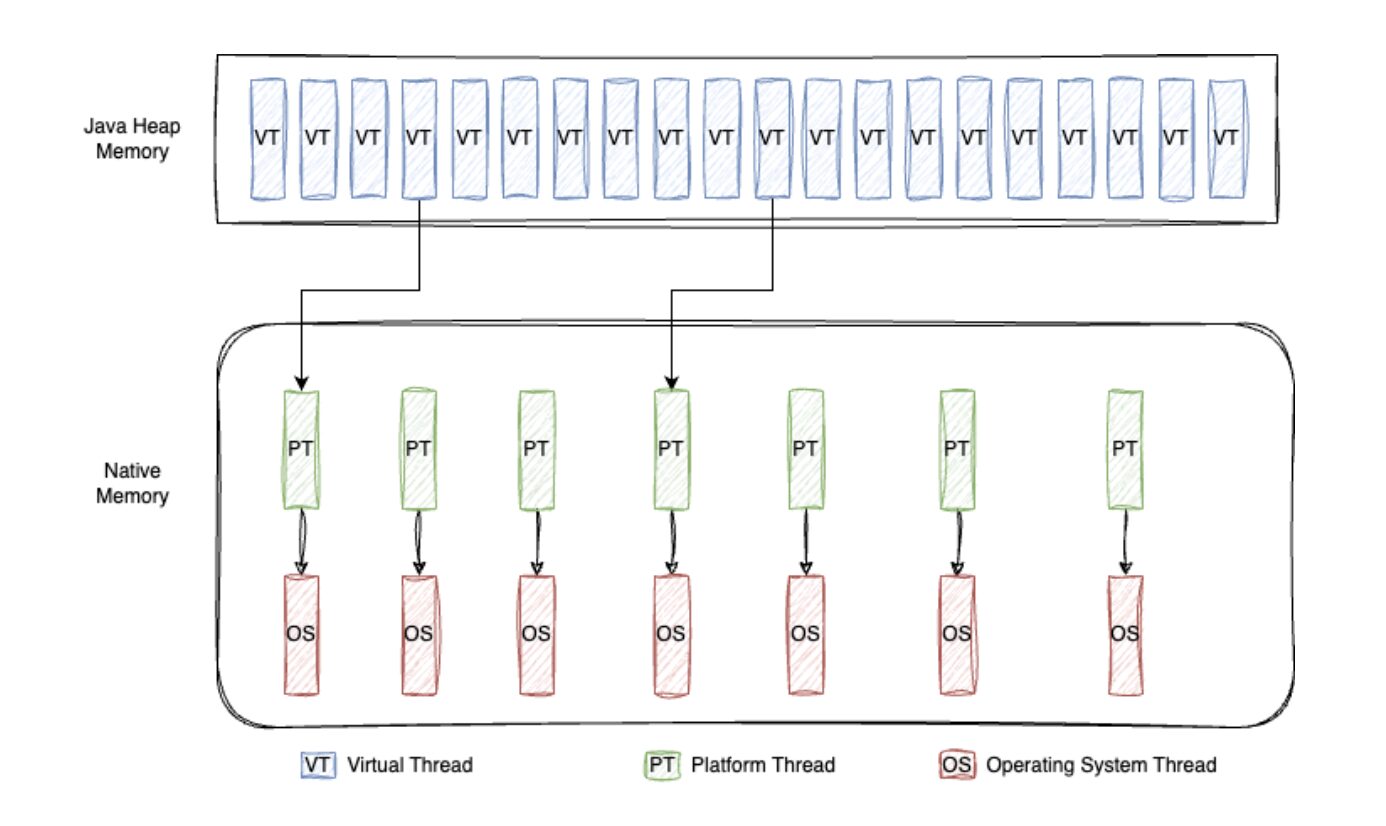
Cuando el hilo de carrera ejecuta un hilo virtual, monitorea la tarea para detectar cualquier operación de bloqueo — por ejemplo, una operación de I/O como una llamada de red o un comando sleep. Cuando ocurre una operación de bloqueo, el hilo virtual es desmontado (pausado) y el hilo de carrera devuelve la tarea a la cola. Luego, el hilo de plataforma toma la siguiente tarea de la cola y comienza a ejecutarla, desbloqueando la tarea anterior una vez que se recibe la respuesta.
Este mecanismo permite que los hilos virtuales sean muy eficientes para manejar tareas limitadas por I/O, donde esperar recursos externos (como consultas a bases de datos, llamadas a servicios web, etc.) es común. Debido a que los hilos virtuales no están atados a hilos de plataforma específicos, pueden ser suspendidos y reanudados sin bloquear el hilo subyacente del sistema operativo. Esto mejora significativamente el rendimiento sin necesidad de crear grandes cantidades de costosos hilos del sistema operativo.
De Virtual Threads a la Práctica: Evaluación del Rendimiento
Hasta ahora, hemos abordado los conceptos fundamentales de los hilos virtuales y su potencial para mejorar la escalabilidad.
A continuación, llevaremos a cabo una serie de experimentos para comparar el rendimiento de los hilos virtuales y tradicionales en una aplicación web Spring Boot, analizando cómo la cantidad de hilos y las latencias de E/S impactan el rendimiento en escenarios de alta concurrencia.
Para este análisis, creamos un sistema de prueba que simula una aplicación de reserva de vuelos. Las principales acciones que realizan los usuarios son:
1. Reservar asiento (bookSeat): El usuario selecciona un vuelo y reserva un asiento.
2. Cancelar reserva (cancelSeat): El usuario cancela una reserva previamente hecha.
3. Consultar asientos disponibles (getAvailableSeats): El usuario consulta la cantidad de asientos disponibles para un vuelo.
Estas acciones son típicas en un entorno de alta concurrencia, lo que convierte al sistema de reservas en un excelente candidato para probar la eficiencia de los hilos virtuales frente a los tradicionales.

Aspectos Clave del Sistema de Reservas
Modelo de Datos
El objeto principal del dominio es Flight, que contiene información sobre el vuelo, como los asientos disponibles, los asientos reservados y el número de vuelo.


Repositorio
El sistema interactúa con una interfaz de repositorio, FlightRepositoryPort, que podría ser implementada con diferentes almacenes de datos, como una base de datos en memoria.

Utilizaremos una implementación muy simple con almacenamiento de datos en memoria, que es ideal para fines de desarrollo o pruebas.


Servicio de Reservas
Ahora necesitamos un servicio que implemente la funcionalidad de reserva del BookingServicePort.

El método simulateIO() agrega una demora para simular operaciones de entrada/salida del mundo real (por ejemplo, llamadas a redes o consultas a bases de datos).

El método de reserva de asientos acepta un único parámetro: el número de vuelo. Dado que estamos utilizando almacenamiento en memoria, no habrá retrasos relacionados con operaciones de entrada/salida como en los sistemas reales. Por lo tanto, al inicio del método, llamamos al método simulateIO().
Luego, recuperamos el vuelo del repositorio utilizando, reservamos un asiento y guardamos los cambios en el repositorio.

Los demás métodos se implementarán de la misma manera.
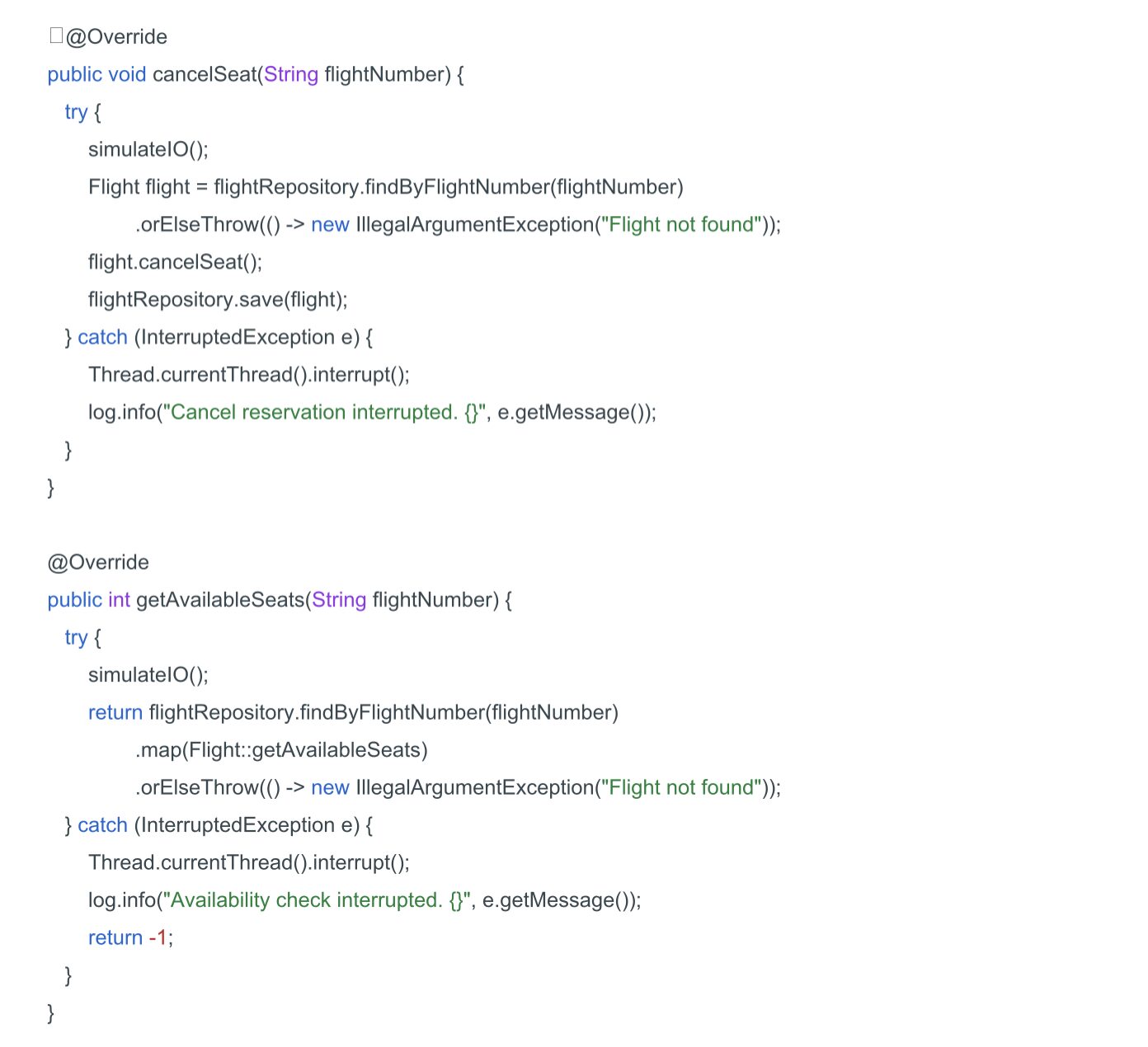
Así que la implementación básica del servicio de reserva de vuelos está completa. Ahora, realicemos pruebas de rendimiento ejecutándolo tanto en hilos tradicionales como en hilos virtuales.
Arquitectura de Pruebas
Usamos JUnit 5 para crear pruebas parametrizadas que evalúan el rendimiento de ambas implementaciones bajo diferentes condiciones de carga (50, 100, 1000, 10 000, 20 000, 50 000 y 100 000 tareas) usando tanto hilos tradicionales como virtuales.
 Crearemos un método para ejecutar múltiples instancias de la misma tarea en un entorno multihilo y medir el tiempo requerido para su finalización.
Crearemos un método para ejecutar múltiples instancias de la misma tarea en un entorno multihilo y medir el tiempo requerido para su finalización.




CountDownLatch se utiliza para garantizar que el hilo actual espere a que todas las tareas paralelas se completen. Se envían al executorService una cantidad de tareas, especificadas por concurrentTasks, dentro de un bucle. Cada tarea ejecuta su método run(), y al finalizar, se llama a latch.countDown() para decrementar el contador.
El método await() bloquea el hilo actual hasta que el contador del latch llegue a cero, lo que indica que todas las tareas han finalizado. Una vez que todas las tareas se completan, se registra el tiempo de finalización y se calcula el tiempo total empleado en ejecutar las tareas.
Ahora, vamos a crear una prueba para evaluar el rendimiento utilizando hilos virtuales.
 Todo está listo para ejecutar la prueba. Veamos qué resultados obtenemos.
Todo está listo para ejecutar la prueba. Veamos qué resultados obtenemos.
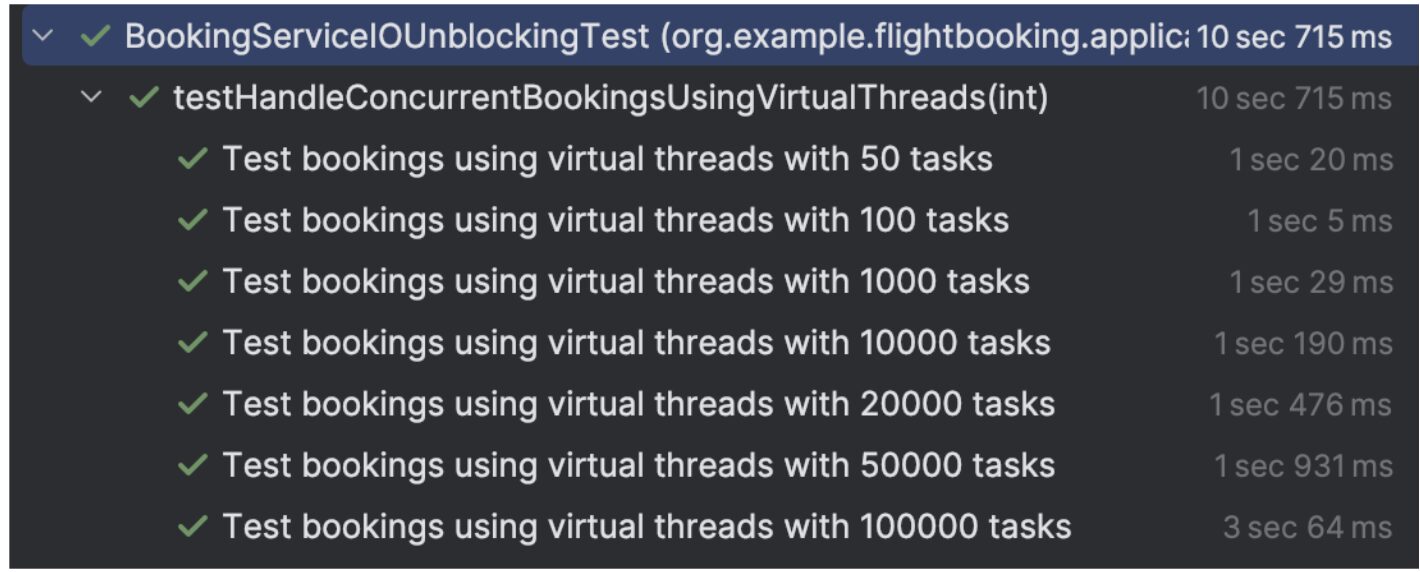
El tiempo de ejecución aumenta con el número de tareas paralelas, pero el aumento del tiempo no es lineal en relación con el número de tareas. Esto indica que el rendimiento no empeora significativamente, incluso con un gran número de tareas. Ahora veamos cómo se comportarán los hilos tradicionales.
El test para hilos tradicionales será similar, con la excepción de que se debe especificar el número de hilos nThreads en el pool del servicio de ejecución (Executor). Este es el número máximo de hilos que pueden estar activos simultáneamente dentro del ExecutorService.

Existen recomendaciones para tareas CPU-bound de usar un número de hilos igual al número de núcleos del procesador. Para tareas I/O-bound, no hay una fórmula universal para calcular el número óptimo de hilos. Sin embargo, se puede utilizar la siguiente fórmula aproximada:
Número de hilos = (T_IO / T_CPU) × Número de procesadores
Donde:
· T_CPU es el tiempo que el hilo pasa realizando cálculos.
· T_IO es el tiempo que el hilo pasa esperando operaciones de entrada/salida.
· Número de procesadores es la cantidad de núcleos disponibles en el procesador.
Ahora, busquemos el número óptimo de hilos para nuestra tarea concreta, comenzando con el valor obtenido de esta fórmula.
Número de hilos = (0.99 / 0.01) × 5 = 495
Utilizaremos un valor inicial de nThreads igual a 500. A continuación se presenta una tabla con los resultados obtenidos al modificar el valor de nThreads en comparación con los hilos virtuales.
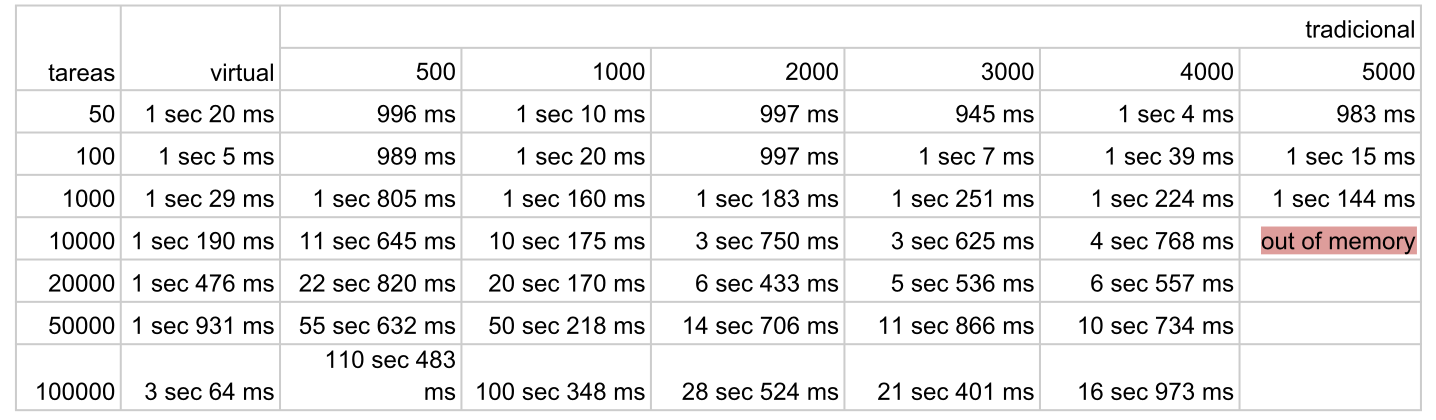
Para una mejor visualización, representémoslo en forma de gráfico:
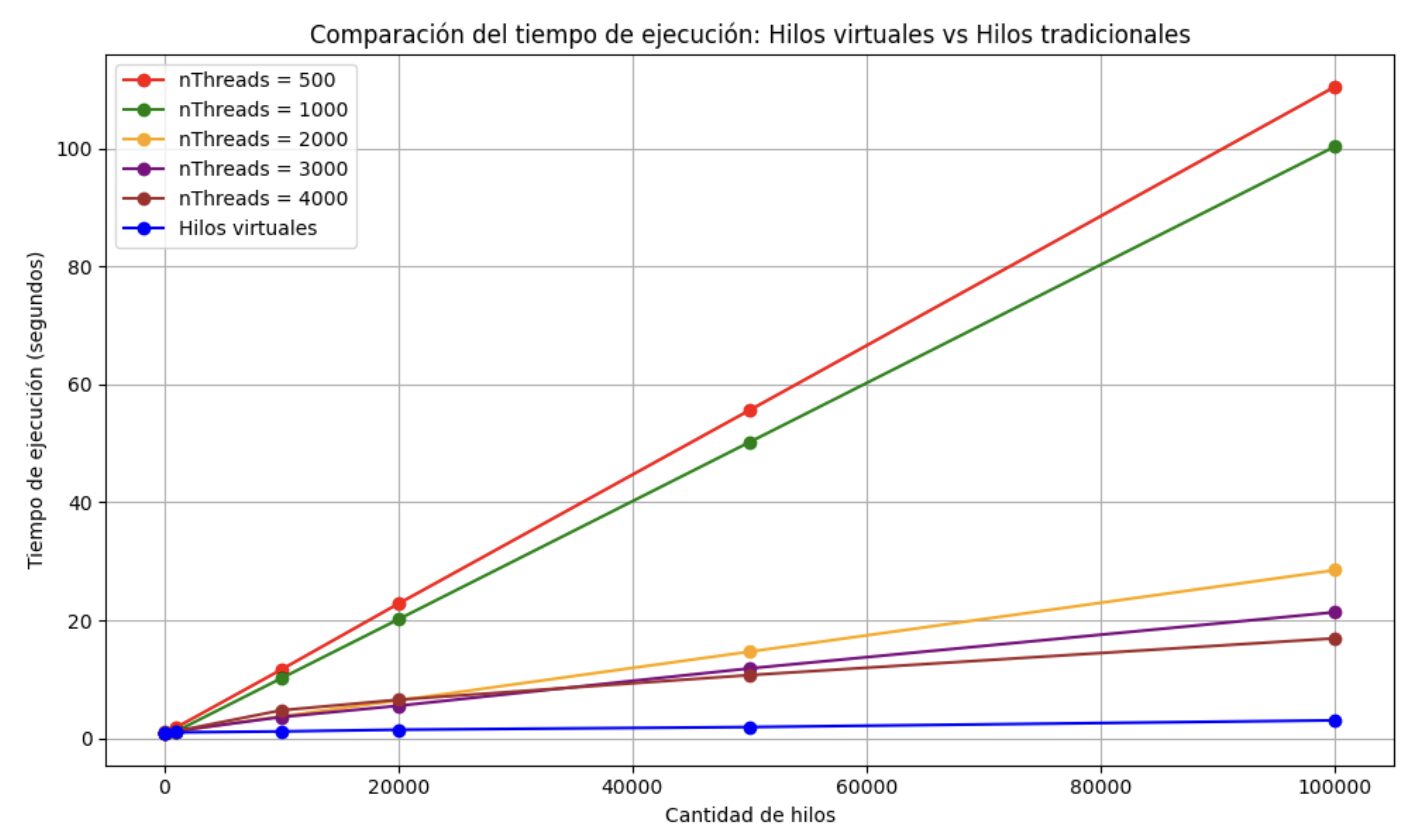
Se observa que al aumentar la cantidad de hilos tradicionales, los resultados comienzan a aproximarse a los de los hilos virtuales, sin embargo, en determinado momento surgen limitaciones relacionadas con la memoria disponible. Esto se debe a que los hilos tradicionales continúan ocupando el procesador mientras esperan.
Hasta ahora, hemos comparado el rendimiento de los hilos virtuales y tradicionales utilizando un ejemplo simplificado de un servicio de reserva de boletos. Ahora me gustaría demostrar cómo se comportarán los hilos si añadimos secciones críticas.
Servicio de Reservas con secciones críticas
Por ejemplo, si reemplazáramos el almacenamiento en memoria por una base de datos real, cada consulta de vuelo nos devolvería una nueva instancia del objeto. En este caso, el uso de synchronized a nivel del objeto Flight no nos protegería contra la posibilidad de que se guarden simultáneamente diferentes datos del mismo vuelo en la base de datos. La solución más básica sería trasladar las operaciones de obtención del vuelo y de guardado de actualizaciones en la base de datos a un bloque synchronized.

Comparamos el rendimiento con diferentes hilos.
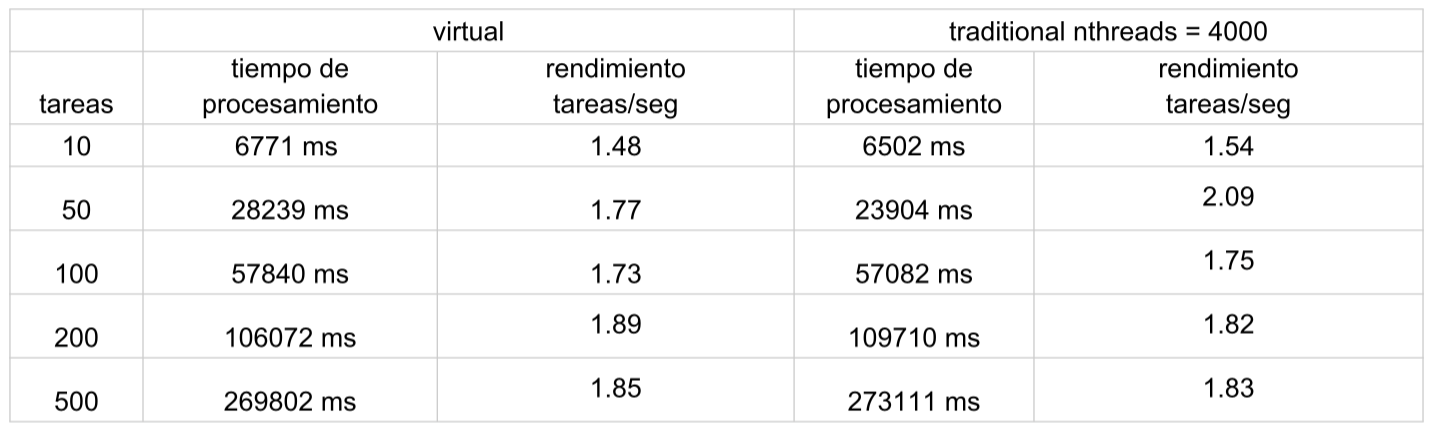
Capacidad de procesamiento similar con distintos tipos de hilos: Observamos que, independientemente de la cantidad de hilos, la capacidad de procesamiento (tasks per second) es prácticamente la misma.
Explicación de la razón: Esto se debe a que, al usar secciones críticas, solo un hilo (ya sea normal o virtual) puede ejecutar esa sección en cualquier momento. Incluso si creas miles de hilos, estos se venobligados a esperar en la cola para obtener el bloqueo y ejecutar la sección crítica de manera secuencial.
¿No bloquean los hilos virtuales los hilos de la plataforma durante operaciones de E/S? La respuesta es sí, pero hay un matiz importante. Al usar bloqueos, el hilo virtual adquiere el monitor. Cuando un hilo virtual realiza una operación de entrada/salida o invoca Thread.sleep(), se desmonta del hilo de la plataforma.
Comportamiento del monitor: Sin embargo, aunque el hilo virtual se desmonta del hilo de la plataforma,
el monitor no se libera. Esto significa que otros hilos (virtuales o no) no pueden acceder a la sección crítica
hasta que el monitor sea finalmente liberado.
¿Cómo mejorar el rendimiento?
Evitar bloqueos
Si el almacenamiento admite actualizaciones optimistas (por ejemplo, versiones de objetos o
transacciones), se pueden eliminar los bloqueos a nivel de servicio.
Minimizar el tiempo bajo bloqueo
Mueva la operación simulateIO() fuera de la sección crítica para reducir el tiempo de retención del
bloqueo.
Usar bloqueos más granulares:
En lugar de un solo bloqueo global para todo el servicio, puede usar bloqueos individuales para
cada vuelo.
En el próximo capítulo, explicaré cómo implementar bloqueos más granulares.
Servicio de Reservas con bloqueos más granulares
Implementemos bloqueos individuales para cada vuelo para reducir la probabilidad de que varios hilos se bloqueen entre sí. Esto se puede lograr utilizando un mapa de bloqueos, donde cada vuelo tenga su propio bloqueo. En lugar de synchronized, utilizaremos ReentrantLock, que ofrece más flexibilidad y control.

Actualizaremos nuestra clase de repositorio para simular un mayor número de vuelos.

Actualizaremos la prueba.

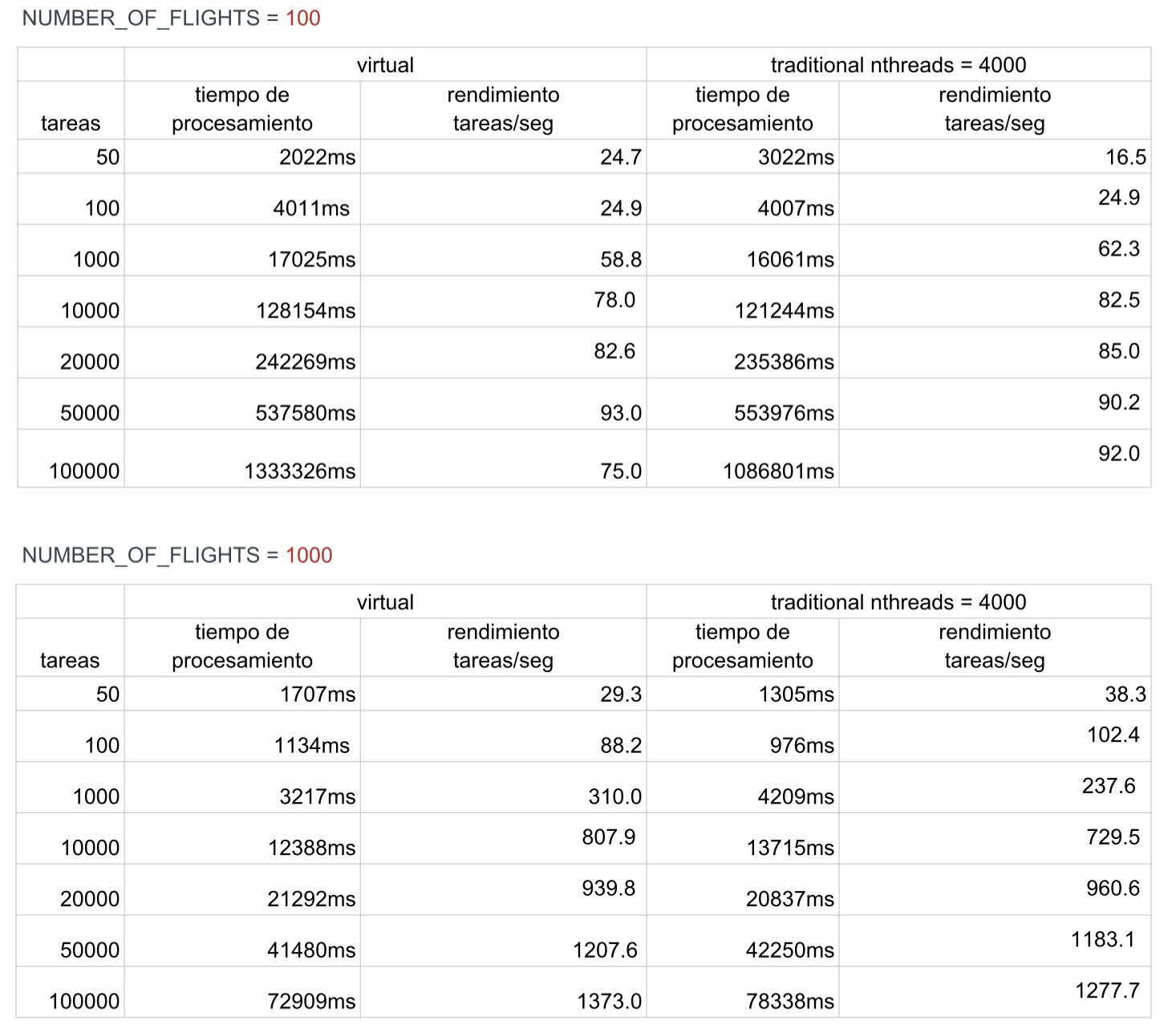
Comparamos el rendimiento con diferentes hilos.
Para una mejor visualización, lo representamos en forma de gráfico:
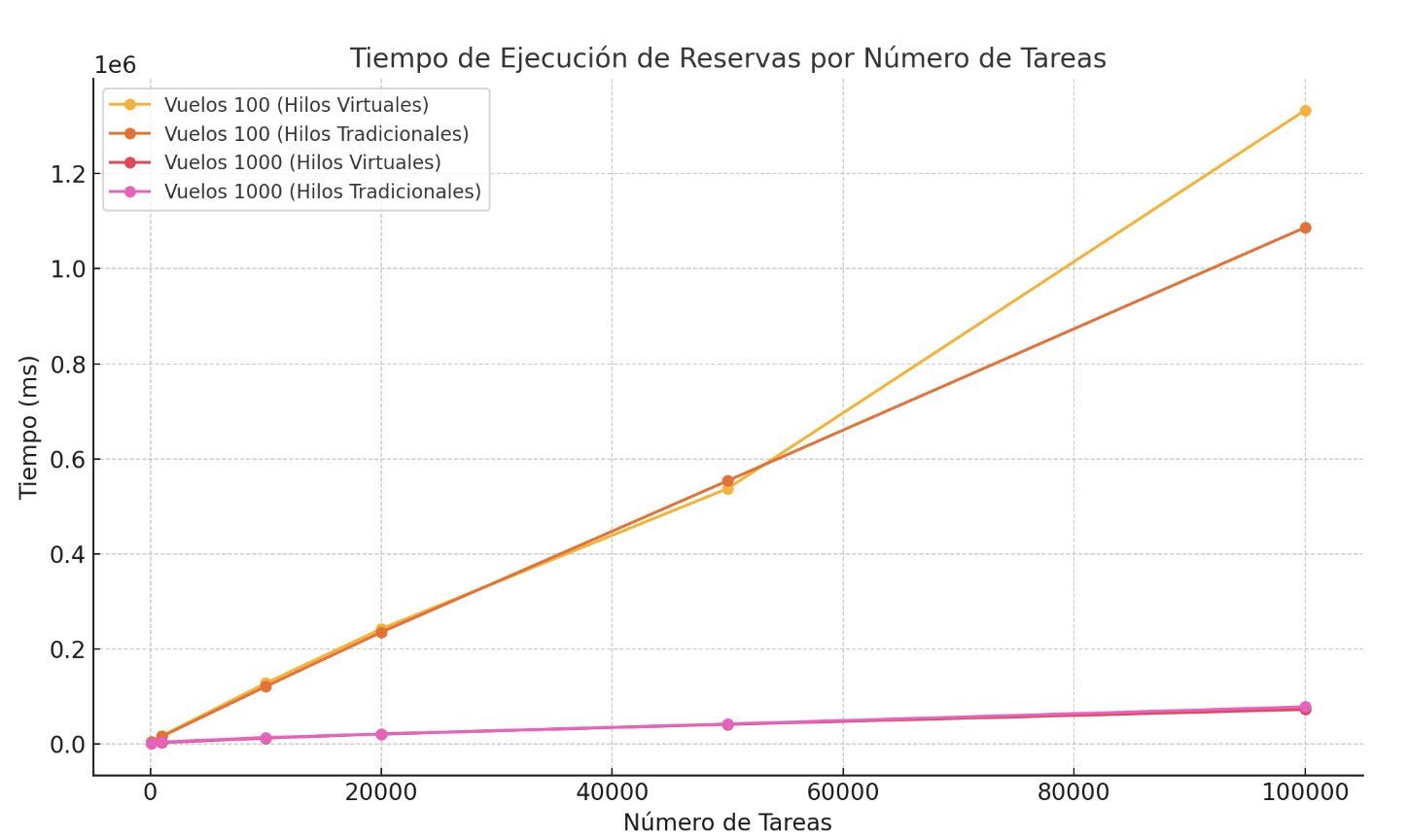
Estos resultados muestran que, cuanto más granulares sean los bloqueos, mayor será el paralelismo. Los hilos que no requieren acceder a la misma parte de los datos pueden ejecutarse simultáneamente, lo que aumenta el rendimiento general. También observamos que, al utilizar bloqueos, los hilos virtuales no tienen ventaja sobre los hilos tradicionales, ya que se pierden los beneficios del I/O no bloqueante al emplear bloqueos.
Comparamos el uso de hilos virtuales y tradicionales en diferentes escenarios de E/S. Ahora me gustaría verificar la afirmación de que no es recomendable utilizar hilos virtuales para tareas intensivas en CPU.
Servicio de Reservas con tareas intensivas en CPU
Creamos una simulación de una tarea intensiva en CPU.
 La utilizamos en nuestro método de reserva en lugar de la simulación de entrada/salida.
La utilizamos en nuestro método de reserva en lugar de la simulación de entrada/salida.
![]()

Realizamos las pruebas y comparamos los resultados.
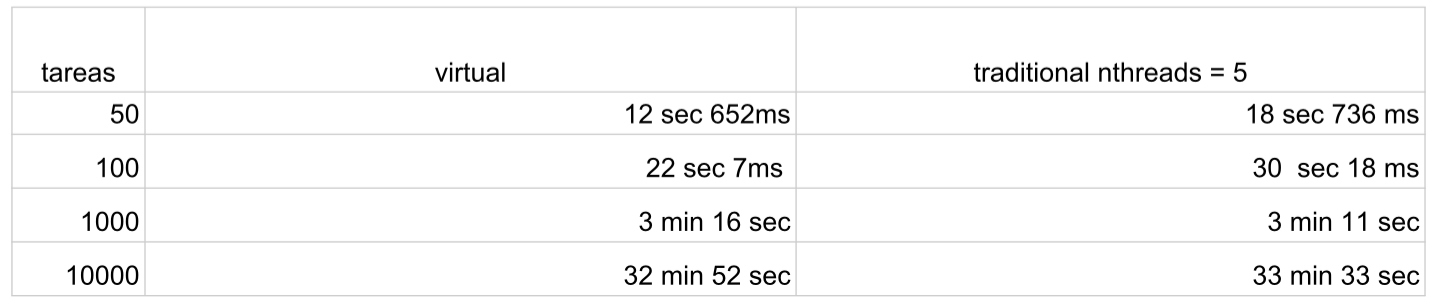
Los resultados muestran que el tiempo de ejecución de estas tareas para ambos tipos de hilos es prácticamente el mismo. Esto confirma la hipótesis de que, aunque los hilos virtuales son eficientes para tareas relacionadas con operaciones de entrada/salida prolongadas, no ofrecen una ventaja significativa en el caso de tareas que requieren un alto uso del procesador.
La razón principal de la ausencia de diferencias radica en el hecho de que las tareas intensivas en CPU dependen en gran medida de la potencia de cálculo del procesador, y no de la capacidad de los hilos para cambiar entre sí de manera eficiente.
En escenarios donde las tareas requieren un uso continuo del procesador, las ventajas de los hilos virtuales, como el menor costo de cambio de contexto, no tienen un impacto significativo en el rendimiento.
Conclusión
En conclusión, los hilos virtuales en Java representan una poderosa herramienta para tareas que implican operaciones de entrada/salida, ya que permiten una creación eficiente de hilos y una gestión de recursos optimizada. Estos hilos son ideales cuando se necesita un alto grado de concurrencia y procesamiento asincrónico, lo que los convierte en una opción excelente para aplicaciones que manejanbases de datos o servicios web remotos.
Sin embargo, cuando se trata de tareas intensivas en CPU, los hilos virtuales no ofrecen un beneficio considerable. En estos escenarios, la capacidad del procesador es lo que determina el rendimiento, y los hilos tradicionales siguen siendo más adecuados para estas tareas.
Es fundamental tener en cuenta que el uso de hilos virtuales pierde su ventaja en contextos donde se emplean bloqueos y operaciones de entrada/salida dentro de bloques sincronizados. En estos casos, las estrategias de paralelismo más efectivas, como el uso de bloqueos más granulados, tienen un impacto más positivo en el rendimiento que el simple uso de hilos virtuales.
Por lo tanto, al elegir entre hilos virtuales y tradicionales, es crucial considerar el tipo de tarea que se va a ejecutar y las características específicas de la aplicación.

